
pyTorch深度学习多层感知机的实现
目录
- 激活函数
- 多层感知机的PyTorch实现
激活函数
前两节实现的传送门
pyTorch深度学习softmax实现解析
pyTorch深入学习梯度和Linear Regression实现析
前两节实现的linear model 和 softmax model 是单层神经网络,只包含一个输入层和一个输出层,因为输入层不对数据进行transformation,所以只算一层输出层。
多层感知机(mutilayer preceptron)加入了隐藏层,将神经网络的层级加深,因为线性层的串联结果还是线性层,所以必须在每个隐藏层之后添加激活函数,即增加model的非线性能力,使得model的function set变大。
ReLU,Sigmoid, tanh是三个常见的激活函数,分别做出它们的函数图像以及导数图像。
#画图使用
def xyplot(x,y,name,size):
plt.figure(figsize=size)
plt.plot(x.detach().numpy(),y.detach().numpy())
plt.xlabel('x')
plt.ylabel(name+'(x)')
plt.show()
#relu x = torch.arange(-8,8,0.01,requires_grad=True) y = x.relu() xyplot(x,y,'relu')
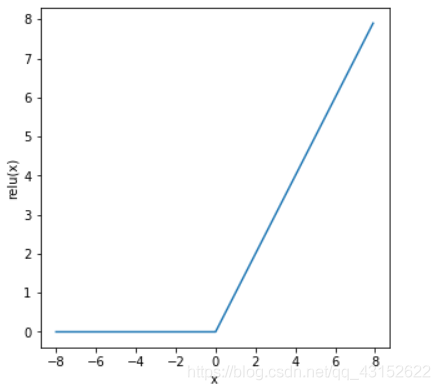
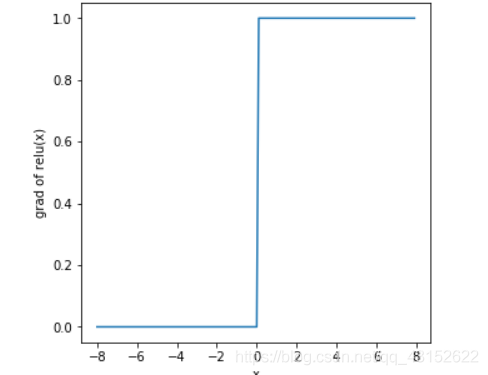
y.sum().backward() xyplot(x,x.grad,'grad of relu')
其它两个激活函数的图像画法类似,分别为x.sigmoid(),x.tanh()
多层感知机的PyTorch实现
实际上多层感知机不过是在linear变换之后添加relu操作,在output layer进行softmax操作
def relu(x): return torch.max(input=x,others,other=torch.tensor(0.0))
max这个方法除了返回tensor中的最大值,还有和maximum函数一样的作用,将input和other进行element-wise的比较,返回二者中的最大值,shape不变。
class MulPeceptron(nn.Module):
def __init__(self,in_features,out_features):
super().__init__()
self.fc = nn.Linear(in_features=in_features,out_features=256)
self.out = nn.Linear(in_features=256,out_features=out_features)
def forward(self,t):
t = t.flatten(start_dim=1)
t = self.fc(t)
t = F.relu(t)
t = self.out(t)
return t
这里就不从零开始实现了,因为softmax和linear model手写过以后,这个只是增加了一个矩阵乘法和一个ReLU操作
以上就是pytorch深度学习多层感知机的实现的详细内容,更多关于pytorch实现多层感知机的资料请关注hwidc其它相关文章!
【文章来源:http://www.yidunidc.com/mg.html 原文提供 欢迎转载】