
python网络爬虫精解之XPath的使用说明
目录
- 一、XPath的介绍
- 二、XPath使用
- 1、选取所有节点
- 2、获取子节点
- 3、获取父节点
- 4、属性匹配
- 5、文本获取
- 6、属性获取
- 7、属性多值匹配
- 8、多属性匹配
- 9、按序选择
- 10、节点轴选择
XPath的使用
一、XPath的介绍
XPath的几个常用规则:
二、XPath使用
1、选取所有节点
test01.html
<book class="item"> <title lang="en" class="item-01">Harry Potter</title> <author class="item-02 name">J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//*')
print(result)
运行程序后得到一个列表:
[<Element html at 0x2252aff0d88>, <Element body at 0x2252aff0e48>, <Element book at 0x2252aff0e88>, <Element title at 0x2252aff0ec8>, <Element author at 0x2252aff0f08>, <Element year at 0x2252aff0f88>, <Element price at 0x2252aff0fc8>]
列表中每个元素代表原test01.html文件中的节点,可以看出节点有html、body、book、title、author、year、price节点。
2、获取子节点
如果想要获取book节点下的author节点,则可将代码编写为:
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//author')
print(result)
这样仅可获得author节点:[<Element author at 0x2252aef8748>]
3、获取父节点
获取当前节点的父节点,主要是父节点的属性值。
以获取父节点book的class属性值为例。
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//title[@class="item-01"]/../@class') #获取title节点的父节点的class属性值
print(result)
【运行结果】
['item']
通过查阅之前test01.html的源码可知,父节点book的class属性值为“item”。
4、属性匹配
我们知道每个节点几乎都带有属性,通过属性匹配我们可以匹配具有相同节点名但属性不同的节点。
通常是将需要匹配的属性放在中括号内。
例如,用属性匹配的方式获取title节点。
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//title[@lang="en"]')
print(result)
【运行结果】
[<Element title at 0x2252afb2a48>]
则得到了title节点。
5、文本获取
一般我们爬取的内容都是文本形式,我们使用text()方式将文本内容提取出来。
在上一个实例的基础上,我们获取标题的具体内容。
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//title[@lang="en"]/text()')
print(result)
【运行结果】
['Harry Potter']
这样我们就得到了具体的标题名称。
6、属性获取
有时候我们想要的数据不在文本内容,而是在节点的属性值里,因此我们还需要学会获取节点的属性值。
常用方式是在需要获取的属性值前面加@符号即可。
例如,我们获取标题title的lang和class这两个属性值。
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//title/@lang')
result.append(html.xpath('//title/@class')[0])
print(result)
【运行结果】
['en', 'item-01']
这样我们就完成了属性值的获取。
7、属性多值匹配
有时候属性值并不只有一个,而是具有多个属性值,像实例中author节点的class属性值,具有两个值item-02和name,通常我们在匹配时使用contains()方法,该方法的第一个参数传入属性名称,第二个参数传入属性值(多个属性值中的任意一个)。
我们以获取作者姓名为例:
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//author[contains(@class,name)]/text()')
print(result)
【运行结果】
['J K. Rowling']
8、多属性匹配
一个节点通常会有多个属性,例如实例中的title节点,就具有lang和class节点,在进行多属性匹配时,使用and符来连接。
from lxml import etree
html = etree.parse('./test01.html',etree.HTMLParser())
result = html.xpath('//title[@lang="en" and @class="item-01"]/text()')
print(result)
【运行结果】
['Harry Potter']
以下是常见的运算符:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GyHoIIVB-1631169770821)(D:\Users\31156\Desktop\网络爬虫\img\img11.jpg)]
9、按序选择
实例test02.html
<bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
我们还是按照之前讲的,获取book节点下的title名。
from lxml import etree
html = etree.parse('./test02.html',etree.HTMLParser())
result = html.xpath('//book/title/text()')
print(result)
【运行结果】
['Harry Potter', 'Learning XML']
这时我们看到有两个标题名,在处理时,我们可以在中括号中传入索引获取指定次序的节点。
获取依次节点的值:
from lxml import etree
html = etree.parse('./test02.html',etree.HTMLParser())
result1 = html.xpath('//book[1]/title/text()')
result2 = html.xpath('//book[2]/title/text()')
print(result1)
print(result2)
【运行结果】
['Harry Potter']
['Learning XML']
还有一些其他方法,例如获取最后一个节点用last()等,其他操作函数可参考:XPath函数
10、节点轴选择
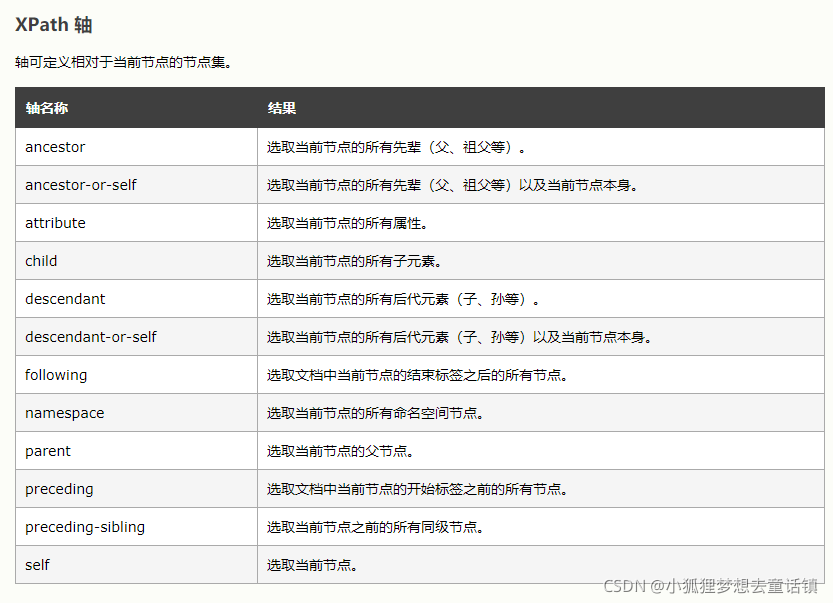
这些节点轴可以帮助我们更快速的进行匹配。
到此这篇关于python网络爬虫精解之XPath的使用说明的文章就介绍到这了,更多相关python XPath内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【本文由http://www.1234xp.com/xgzq.html首发,转载请保留出处,谢谢】