
Java读取PDF中的表格的方法示例
目录
- 一、概述
- 二、环境配置
- 1. 手动导入
- 2. Maven仓库下载导入
- 三、读取PDF中的表格
一、概述
本文以Java示例展示读取PDF中的表格的方法。这里导入Spire.PDF for Javah中的jar包,并使用其提供的相关及方法来实现获取表格中的文本内容。下表中整理了本次代码使用到的主要类、方法及解释,供参考:
二、环境配置
- IntelliJ IDEA 2018(JDK 1.8.0)
- PDF 测试文档
- PDF Jar包:Spire.PDF for Java Version: 4.10.2
Jar包的两种导入方法:
1. 手动导入
将jar包下载到本地,解压。然后执行如下步骤来手动导入:
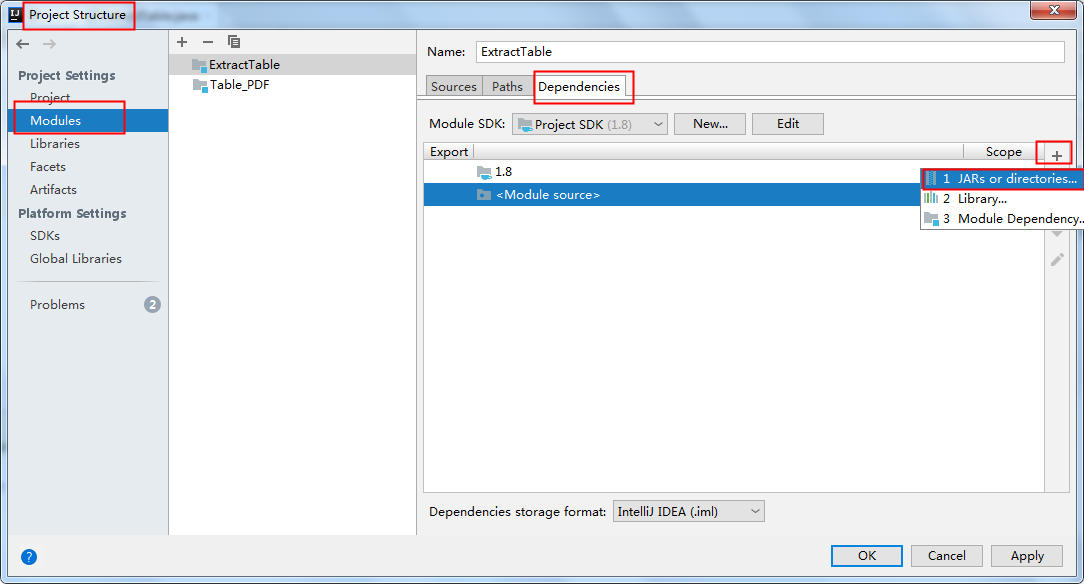
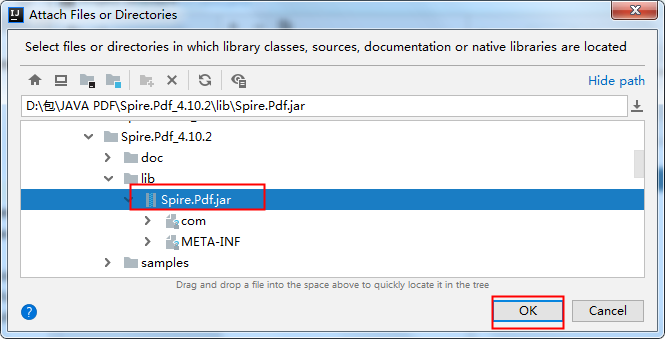
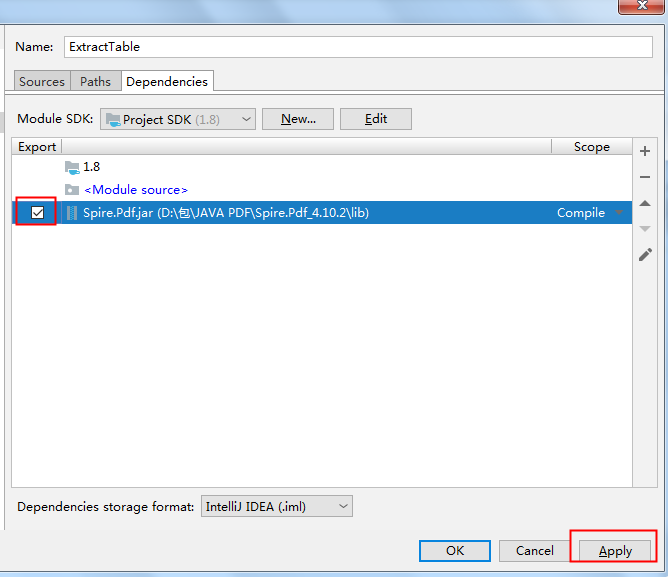
2. Maven仓库下载导入
如果使用maven,需在pom.xml中配置maven路径,指定依赖,如下:
<repositories>
<repository>
<id>com.e-iceblue</id>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>4.10.2</version>
</dependency>
</dependencies>
三、读取PDF中的表格
import com.spire.pdf.*;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTable {
public static void main(String[] args)throws IOException {
//加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("test.pdf");
//创建StringBuilder类的实例
StringBuilder builder = new StringBuilder();
//抽取表格
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists ;
for (int page = 0; page < pdf.getPages().getCount(); page++)
{
tableLists = extractor.extractTable(page);
if (tableLists != null && tableLists.length > 0)
{
for (PdfTable table : tableLists)
{
int row = table.getRowCount();
int column = table.getColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
String text = table.getText(i, j);
builder.append(text+" ");
}
builder.append("\r\n");
}
}
}
}
//将提取的表格内容写入txt文档
FileWriter fileWriter = new FileWriter("ExtractedTable.txt");
fileWriter.write(builder.toString());
fileWriter.flush();
fileWriter.close();
}
}
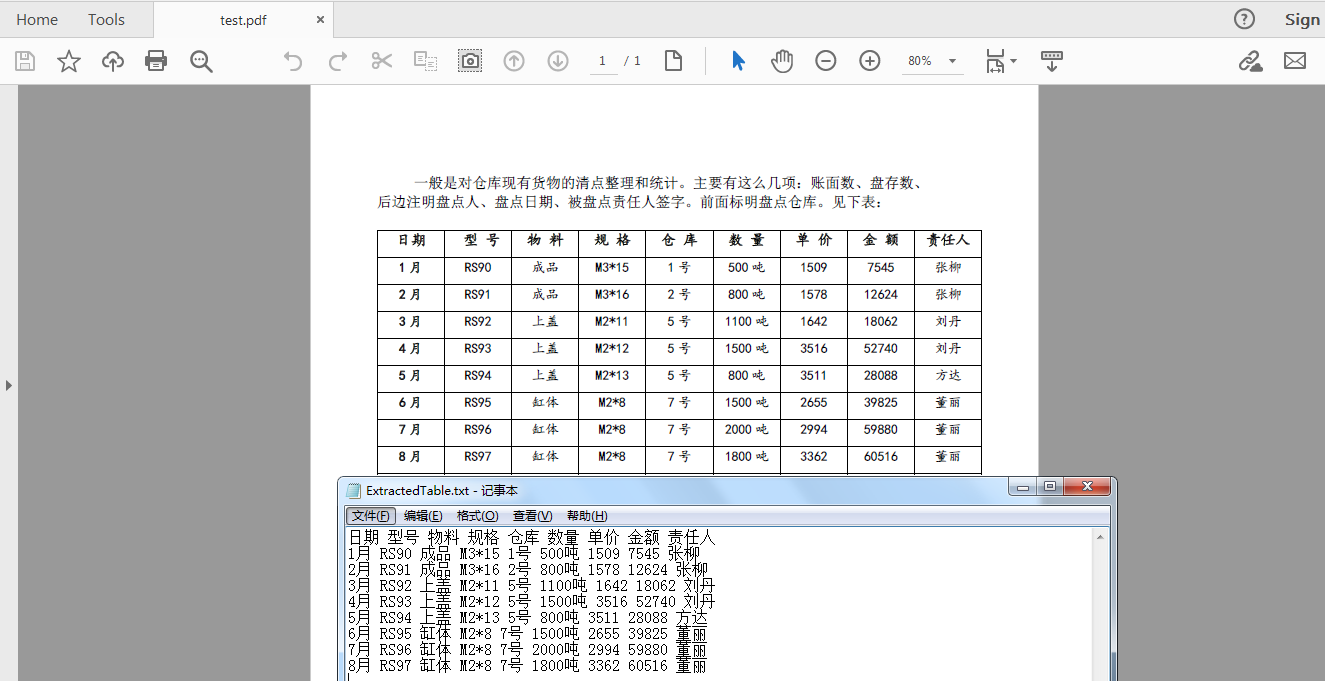
表格内容读取结果:
注意事项:
1. 注意使用的PDF Jar包版本为4.10.2,低于此版本的jar包不支持读取表格;
2. 代码中的文件路径为 F:\IDEAProject\Table_PDF\test.pdf 和 F:\IDEAProject\Table_PDF\ExtractedTable.txt , 文件路径可自定义为其他路径。
到此这篇关于Java读取PDF中的表格的方法示例的文章就介绍到这了,更多相关Java读取PDF表格内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!
【本文出处:国外高防服务器 复制请保留原URL】