
Python调用百度AI实现图片上表格识别功能
目录
- 简介
- 步骤
- 安装百度AI库
- 注册百度AI开放平台
- 调用AipOcr库识别表格文字
- 可能遇到的问题
- 批量操作
- 总结
简介
Python免费调用百度AI实现图片上面的表格识别
步骤
安装百度AI库
!pip install baidu-aip
注册百度AI开放平台
先注册百度AI,获得ID和密钥。注册方法可参考:注册方法 只需走到 “1.6 获取密钥” 即可。然后记录下自己的APP_ID、API_KEY、SECRET_KEY,就可以开始了。

调用AipOcr库识别表格文字
from aip import AipOcr #导入AipOcr模块,用于做文字识别 APP_ID = '*********' # 你申请的 API_KEY = '*********'# 你申请的 SECRET_KEY = '*********'# 你申请的 client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
选择的图片为某化学方程式表(来源于网络)
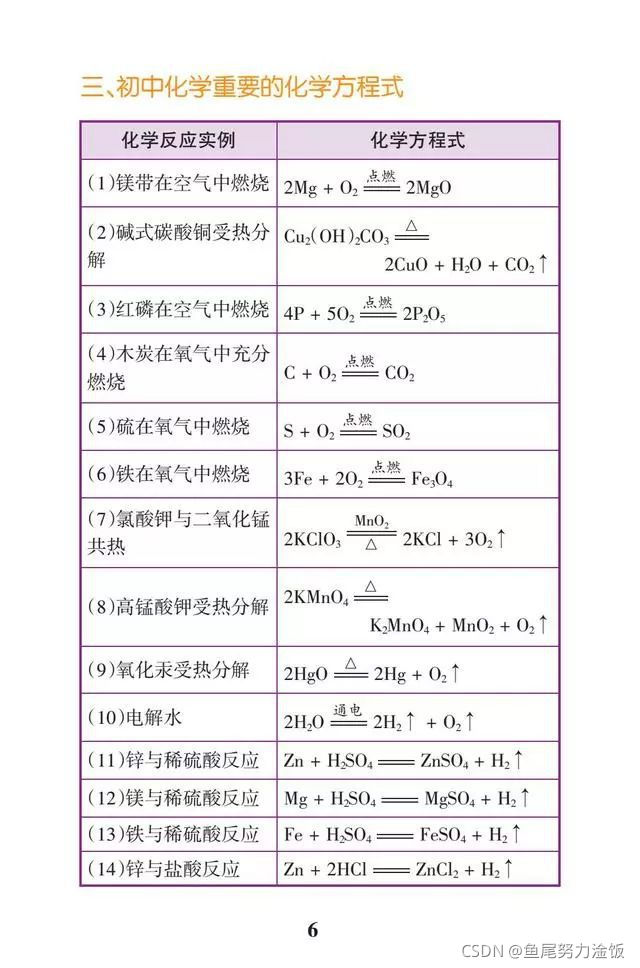
以二进制方式打开图片,读取:
file = "表格图片\\化学方程式表.jpg" pic = open(file,'rb') #以二进制方式打开图片 img = pic.read() #读取 table = client.tableRecognitionAsync(img) #调用表格识别模块 print(table)
然后调用表格识别模块tableRecognitionAsync(),并将返回值存入变量table中并查看:
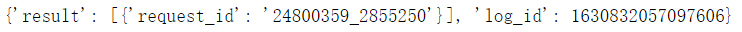
table是一个字典,其中有2个键,一个叫result,一个叫log_id。我们需要的是result中的request_id,可以通过如下语句获取:
request_id = table['result'][0]['request_id'] request_id
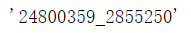
通过这个ID,可以获取识别完成后所保存的Excel表格的下载地址。将request_id传入getTableRecognitionResult()就能获取结果。
result = client.getTableRecognitionResult(request_id) print(result)
打印一下结果result,就能看到下面的内容。其中result_data对应的那个网址就是Excel表格的下载地址。

调用webbrowser库使用webbrowser.open(url)语句自动打开网址进行下载:
url = result['result']['result_data'] import webbrowser # 打开浏览器 webbrowser.open(url)
附:Python 通过浏览器 打开指定网址
1.通过默认浏览器打开网页
import webbrowser
webbrowser.open("http://www.baidu.com")
webbrowser.open(url, new=0, autoraise=True) 在系统的默认浏览器中访问url地址,如果new=0, url会在同一个
浏览器窗口中打开;如果new=1,新的浏览器窗口会被打开;new=2 新的浏览器tab会被打开
2.通过os模块,启动浏览器并打开指定网页
import os
os.system('"C:\Program Files\internet explorer\iexplore.exe" http://www.baidu.com')
3.使用selenium
from selenium import webdriver url='http://www.baidu.com' driver = webdriver.Firefox() driver.get(url)
识别结果如下:
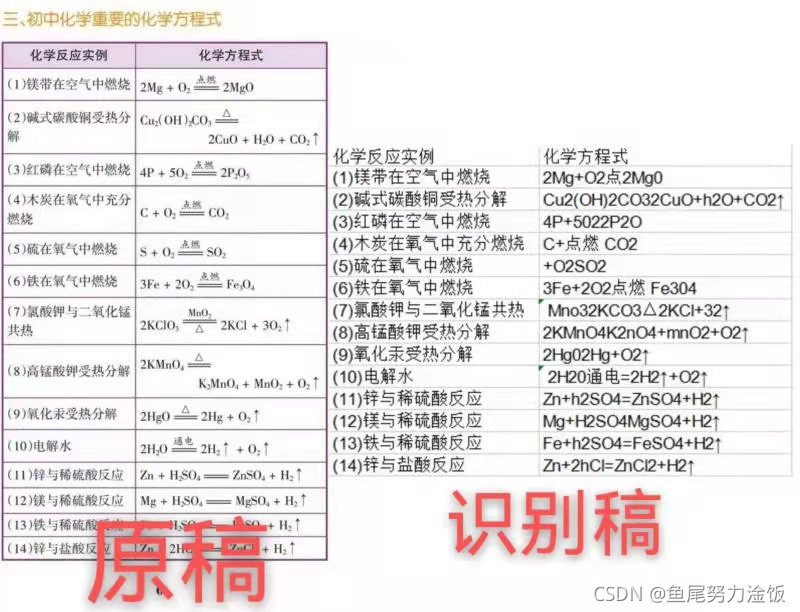
这个Excel文件有6张工作表,具体包含与图片中表格内容的对应关系如下。body储存表格部分的内容,header储存表头的文字,footer储存表尾的文字。
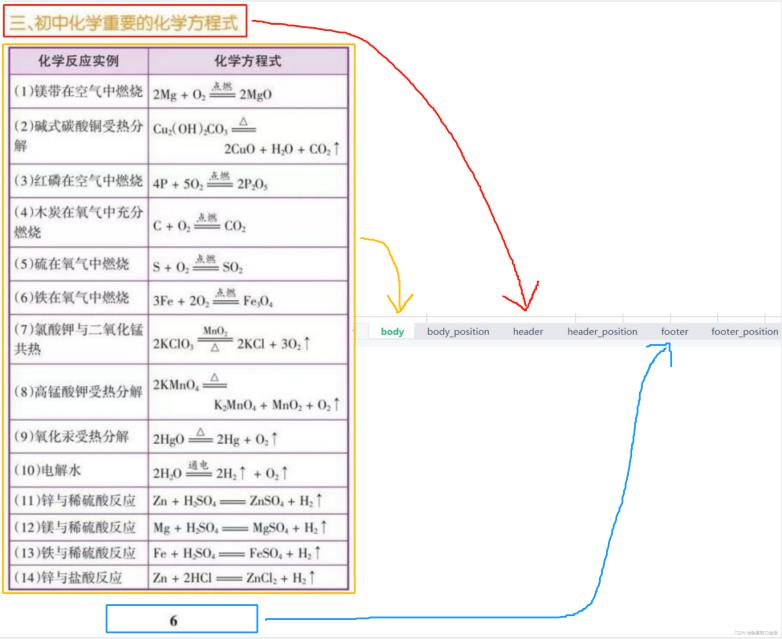
识别效果并非完美,但是整体看来还行,当然,原稿越清晰,识别效果越好。
可能遇到的问题
在开始前,需要检查图片的大小,必须在1K~4M之间,不然会报错“‘error_msg': ‘image size error, image is too big or too small, upper limit 4M, lower limit 1k, please check your param'”。
批量操作
先获取所有图片的路径,存入pictures列表。结果如下。
#获取路径下所有图片文件,并存入列表
import os
work_path = "表格图片\\"
pictures=[] # 存储文件夹内所有文件的路径(包括子目录内的文件)
for root, dirs, files in os.walk(work_path):
path = [os.path.join(root, name) for name in files]
pictures.extend(path)
pictures
然后将所有图片逐个传入表格识别接口,获取其请求ID及存有识别结果的Excel文件的下载地址。在提取Excel下载路径之前,需要先判断识别是否完成。这是通过识别结果返回的字典中的'ret_msg'对应的值来判断的。只有当它是“已完成”时,才能获得下载链接。此处用了while循环,每隔2秒刷新一下状态,直到状态是“已完成”时,才提取链接。然后使用requests.get()获取下载链接信息,写入Excel文件。Excel自动命名及下载结果如图。
from aip import AipOcr #导入AipOcr模块,用于做文字识别
import time #时间模块
import requests #用于HTTP请求
APP_ID = '24800359' # 你申请的
API_KEY = 'PrmTtmrqkeaqhvxOPEN4eZVt'# 你申请的
SECRET_KEY = 'LOFpCH6wpLV7xZPG0DTcvV4x1Sqyvmk9'# 你申请的
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
#提交识别请求,并储存所有请求ID
for picture in pictures:
pic = open(picture,'rb') #以二进制方式打开图片
img = pic.read() #读取
table = client.tableRecognitionAsync(img) #调用表格识别模块
request_id = table['result'][0]['request_id']
#判断识别是否完成,直到完成才根据请求ID获取Excel下载路径
result = client.getTableRecognitionResult(request_id) #通过ID获取识别结果
while result['result']['ret_msg'] != '已完成': #如果状态是“已完成”,才能获取下载地址
time.sleep(2) #暂停2秒再刷新
result = client.getTableRecognitionResult(request_id) #持续刷新,直到满足条件
download_path = result['result']['result_data']
#下载并将Excel文件名设为图片名
excel_name = picture.split(".")[0] + ".xls" #让excel文件的名字与图片相同
excel = requests.get(download_path) #抓取下载链接
file = open(excel_name, 'wb') #新建excel文件
file.write(excel.content) #写入excel文件并保存
总结
到此这篇关于Python调用百度AI实现图片上表格识别功能的文章就介绍到这了,更多相关Python调用百度AI识别表格内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章出处:香港多ip服务器 复制请保留原URL】