
Python函数的作用域及内置函数详解
目录
- 1.函数的作用域
- 2.函数的调用详解
- 3.内置函数
- 总结
1.函数的作用域
-- 内置
-- 全局,顶格写
-- 局部,函数内部
a = 34 #全局变量
def run():
b = 44 #局部变量
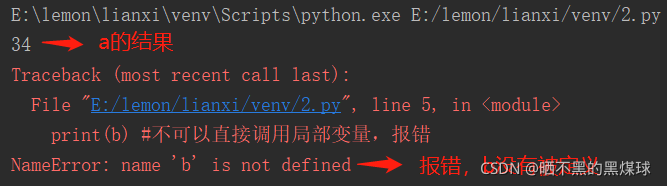
print(a)
print(b) #不可以直接调用局部变量,报错
运行结果:
c = 12
def run(a):
print(a)
b = 33
run(5)
# 一个全局变量c
# 两个局部变量a,b
# 函数的参数也是局部变量
运行结果:
5
局部 VS 全局
-- 局部空间(函数内)获取全局变量,Yes
-- 全部空间(函数外)获取局部变量,No,但可以间接通过返回值 return 获取
-- 全局空间(函数外)修改局部变量,No
-- 局部空间(函数内)修改全部变量,Yes,但必须要声明,global 全局变量名
siwei = 99
def run():
print('函数执行')
print(siwei)# 调用全局变量,可以正常使用
run()
运行结果:
函数执行
99
siwei = 99
def run():
print('函数执行')
a = 88
print(siwei)# 调用全局变量,可以正常使用
return a #用返回值,返给全局变量result
result = run()
print(result)
运行结果:
函数执行
99
88
siwei = 99
def run():
print('函数执行')
a = 88
print(siwei)# 调用全局变量,可以正常使用
return a #用返回值,返给全局变量result
result = run()
print(result)
运行结果:
100
2.函数的调用详解
注意:
-- 函数必须先定义再调用
-- 不同函数定义的先后顺序无关
-- 函数体内可以调用函数自己本身,但一般不这样使用,容易出错
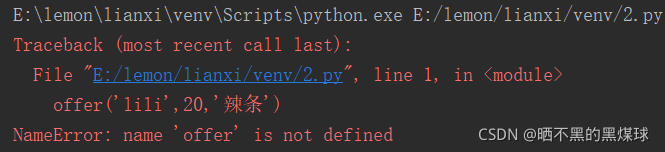
# 还没定义函数就直接调用,所以会报错
offer('lili',20,'辣条')
def eat(name,food):
print('{} 最喜欢吃 {}'.format(name,food))
def offer(name,money,food):
print('恭喜 {} 拿到 {}k offer'.format(name,money))
eat(name,food)
运行结果:
# 一个函数当中是可以去调用另外一个函数的
def eat(name,food):
print('{} 最喜欢吃 {}'.format(name,food))
def offer(name,money,food):
print('恭喜 {} 拿到 {}k offer'.format(name,money))
eat(name,food)
offer('lili',20,'辣条')
运行结果:
恭喜 lili 拿到 20k offer
lili 最喜欢吃 辣条
# 两个函数位置互换是不影响结果的
def offer(name,money,food):
print('恭喜 {} 拿到 {}k offer'.format(name,money))
eat(name,food)
def eat(name,food):
print('{} 最喜欢吃 {}'.format(name,food))
offer('lili',20,'辣条')
运行结果:
恭喜 lili 拿到 20k offer
lili 最喜欢吃 辣条
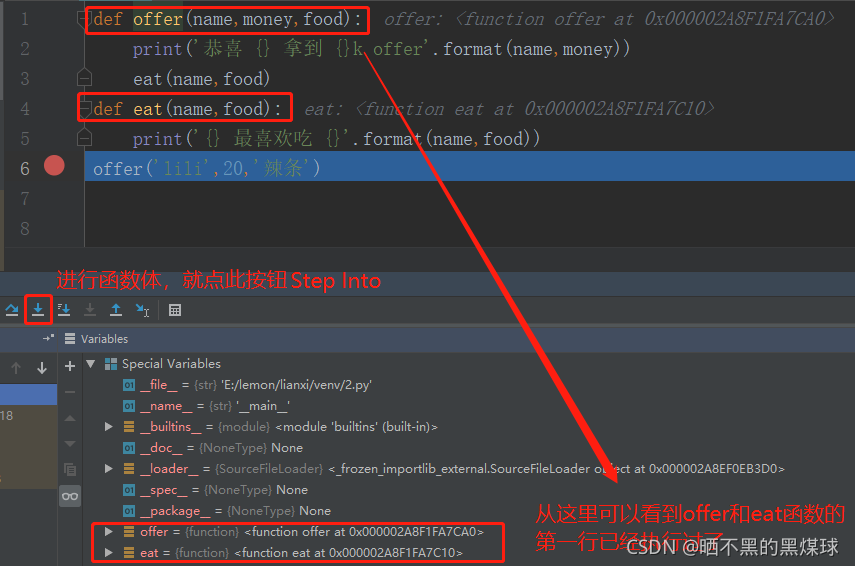
可以通过Debug模式来详细查看一下代码的运行过程
offer 和 eat 函数第一行被执行,函数体里的代码不会被执行
当offer 被调用时,代码自动找offer函数,然后进入函数体内,然后执行eat 函数
代码自动找eat 函数,然后进入函数体
# 函数自己可以调用自己本身,但会报递归错误
def run():
print('正在运行!')
run()
run()
运行结果:
RecursionError: maximum recursion depth exceeded while calling a Python object
递归错误:调用Python对象时超过的最大递归深度
3.内置函数
enumrate():获取列表的索引值与元素值
list1 = ['a','b',1,2]
for i in enumerate(list1):
# 输入结果是数据类型是元组
print(i)
for index,value in enumerate(list1):
# 输出结果:索引值是int类型,元素值是什么数据类型就是什么类型
print(index,value)
运行结果:
(0, 'a') ====> tuple
(1, 'b')
(2, 1)
(3, 2)
0 a ====> 0 int a str
1 b
2 1====> 2 int 1 int
3 2
eval():去掉字符串两边的引号
string = '1 + 1' string1 = '7.8 + 4.5' string2 = '(1,2,3)' print(string,type(string)) # 去掉引号,相当于变成了算数运算 print(eval(string),type(eval(string))) print(eval(string1),type(eval(string1))) # 去掉引号,相当于变成了元组 print(eval(string2),type(eval(string2)))
运行结果:
1 + 1 <class 'str'>
2 <class 'int'>
12.3 <class 'float'>
(1, 2, 3) <class 'tuple'>
zip():用于将可迭代的对象作为参数,按索引号打包成一组一组
title = ['id','name','url']
row = ['1','lili','http://www.baidu1.com']
# zip迭代每一个元素,按索引号打包成一组,然后通过dict转换成字典
result = dict(zip(title,row))
print(result)
# 列表,元组都可以转换成字典
title1 = ('id','name','url')
row1 = ['2','lili','http://www.baidu2.com']
result1 =dict(zip(title1,row1))
print(result1)
运行结果:
{'id': '1', 'name': 'lili', 'url': 'http://www.baidu1.com'}
{'id': '2', 'name': 'lili', 'url': 'http://www.baidu2.com'}
a = [1,2,3]
b = ('a','b','c')
c = 'qaz'
result = dict(zip(a,c))
result1 = dict(zip(a,b))
result2 = dict(zip(b,c))
print(result)
print(result1)
print(result2)
运行结果:
{1: 'q', 2: 'a', 3: 'z'}
{1: 'a', 2: 'b', 3: 'c'}
{'a': 'q', 'b': 'a', 'c': 'z'}
sum(iterable[, start]):求和,求和的类型必须是数字
terable – 可迭代对象,如:列表(list)、元组(tuple)、集合(set)、字典(dict)
start – 指定相加的参数,如果没有设置这个值,默认为0
所以 sum(1,2,3) 是错误的,sum(必须是可迭代对象)
list1 = [2,3,4]
tuple1 = (1,1,1)
dict1= {60.5:'chinese',70:'math'}
set1 = {1,2,3}
print(sum(list1,1))#列表中2,3,4 加上start的值1
print(sum(tuple1))#元组中1,1,1加上默认start的值0
print(sum(dict1))#字典中相加的是key的值,key若不是数字会报错
print(sum(set1))#集合里必须是一层,不能嵌套其他层
运行结果:
10
3
130.5
6
max():求最大值
min() :求最小值
list1 = [1,2,3] print(max(list1)) print(max(3,4,5)) print(min(list1)) print(min(4,5,6))
运行结果:
3
5
1
4
id():查看内存地址
a = 10 b = 10 # 不可变类型(字符串,元组等),内存地址一样 print(id(a)) print(id(b)) # 可变类型(列表,字典),内存地址不一样 c = [1,2,3] d = [1,2,3] print(id(c)) print(id(d))
运行结果:
140716744443840
140716744443840
1975790732416
1975791019584
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注hwidc的更多内容!
【文章由:韩国高防服务器 提供,感谢支持】