
Python 列表与链表的区别详解
目录
- python 列表和链表的区别
- 列表的实现机制
- 链表
- 链表与列表的差异
python 列表和链表的区别
python 中的 list 并不是我们传统意义上的列表,传统列表——通常也叫作链表(linked list)是由一系列节点来实现的,其中每个节点都持有一个指向下一节点的引用。
class Node: def __init__(self, value, next=None): self.value = value self.next = next
接下来,我们就可以将所有的节点构造成一个列表了:
>>> L = Node("a", Node("b", Node("c", Node("d"))))
>>> L.next.next.value
'c'
这是一个所谓的单向链表,双向链表的各节点中还需要持有一个指向前一个节点的引用
但 python 中的 list 则与此有所不同,它不是由若干个独立的节点相互引用而成的,而是一整块单一连续的内存区块,我们通常称之为“数组”(array),这直接导致了它与链表之间的一些重要区别。
例如如果我们要按既定的索引值对某一元素进行直接访问的话,显然使用数组会更有效率。因为,在数组中,我们通常可以直接计算出目标元素在内存中的位置,并对其进行直接访问。而对于链表来说,我们必须从头开始遍历整个链表。
但是具体到 insert 操作上,情况又会有所不同。对于链表而言,只要知道了要在哪里执行 insert 操作,其操作成本是非常低的,无论该列表中有多少元素,其操作时间大致上是相同的。而数组就不一样了,它每次执行 insert 操作都需要移动插入点右边的所有元素,甚至在必要的时候,我们可能还需要将这些列表元素整体搬到一个更大的数组中去。
也正因如此,append 操作通常会采取一种被称为动态数组或‘向量'的指定解决方案,其主要想法是将内存分配的过大一些,并且等到其溢出时,在线性时间内再次重新分配内存。但这样做似乎会使 append 变得跟 insert一样糟糕。其实不然,因为尽管这两种情况都可能会迫使我们去搬动大量的元素,但主要不同点在于,对于 append 操作,发生这样的可能性要小得多。事实上,如果我们能确保每次所搬入的数组都大过原数组一定的比例(例如大20%甚至100%),那么该操作的平均成本(或者说得更确切一些,将这些搬运开销均摊到每次 append 操作中去)通常是常数!
数组数据是连续的,一般需要预先设定数据长度,不能适应数据动态的增减,当数据增加是可能超过预设值,需要要重新分配内存,当数据减少时,预先申请的内存未使用,造成内存浪费。链表的数据因为是随机存储的,所以链表可以动态的分配内存,适应长度的动态变化
1.数组的元素是存放在栈中的,链表的元素在堆中
2.读取操作:数组时间复杂度为O(1),链表为O(n)
3.插入或删除操作:数据时间复杂度为O(n),链表为O(1)
列表
关于列表的存储:
列表开辟的内存空间是一块连续的内存,把这个内存等分成几份(单位是字节),他是连续存储的。
如果一个列表长度已满,再append添加元素的话,会在内存中重新开辟一个2倍的内存空间以存储新元素,原列表内存会被清除。
列表与链表复杂度:
按元素值查找:
按顺序查找,复杂度是一样的。
按二分查找,链表没法查找.
按下标查找:
列表是O( 1 )
链表是O(n)
在某元素后插入:
列表是O(n)
链表是O( 1 )
删除某元素:
列表是O(n)
链表是O( 1 )
链表------->列表相对应的数据结构
链表是一种线性数据结构(与树形结构相对),不是进行连续存储的。
链表中每一个元素都是一个对象,每个对象称为一个节点,包含有数据域key和执行下一个节点的指针next。通过各个节点之间的相互连接,最终串联成一个链表。
1、存储的过程中,需要先创建节点,然后进行定义。
# 节点定义: class Node( object ): def __init__( self ,item): self .item = item # 数据域 self . next = None # 指针域 n1 = Node( 1 ) n2 = Node( 2 ) n3 = Node( 3 ) n1. next = n2 n2. next = n3 # 通过 n1 找到n3的值 print (n1. next . next .item)
只保留头结点,执行第一个位置,剩下的都是next去指定。
2、链表遍历:(头节点的变动)
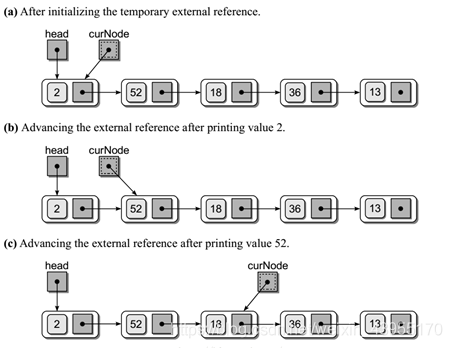
# 节点定义: class Node( object ): def __init__( self ,item): self .item = item # 数据域 self . next = None # 指针域 n1 = Node( 1 ) n2 = Node( 2 ) n3 = Node( 3 ) n1. next = n2 n2. next = n3 # 通过 n1 找到n3的值 print (n1. next . next .item)
3、链表节点的插入和删除操作(非常方便,时间复杂度低)
插入:
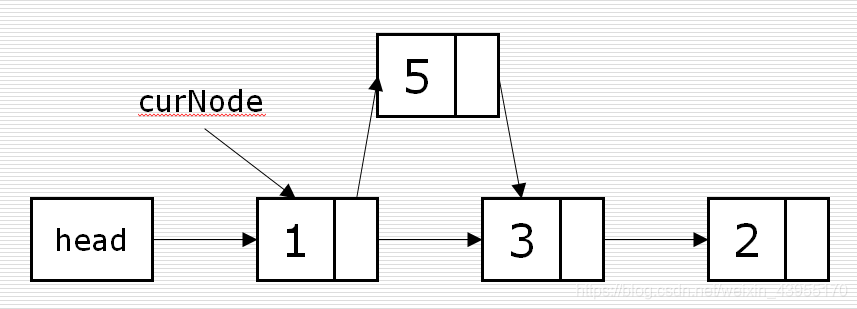
p = Node( 5 ) # 要插入的值 curNode = Node( 1 ) # 标志位 # 顺序不能乱,否则就找不到原链表中的下一个值 p. next = curNode. next # 指定插入值之后的值为标志位之后的值 curNode. next = p # 然后再把原先的链next指向改成插入的值
删除:
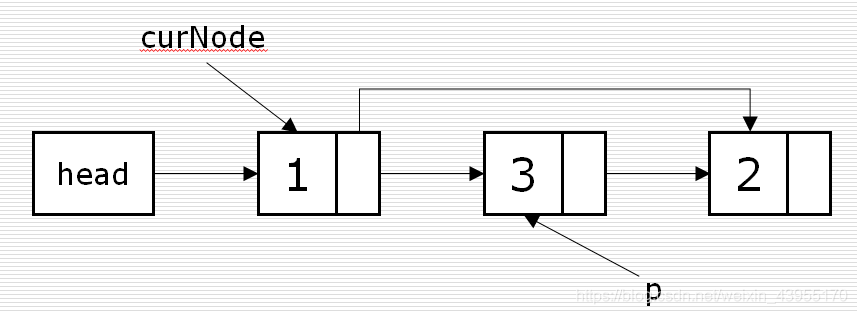
curNode 代表当前值 p = curNode. next # 表示要删除的数 curNode. next = p. next # 重新指定建立链表 del p 删除数
4、建立链表(单链表)

1)头插法:是在head头节点的位置后插入数;得到的链表与原先的列表顺序是相反的。
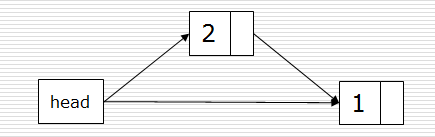
def createLinkListF(li):
l = Node() # 始终指向头节点
for num in li:
s = Node(num)
s. next = l. next
l. next = s
return l
2)尾插法:在链表的尾巴上插入。相当于是追加,必须时刻记住尾巴在哪儿
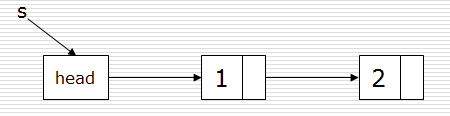
def createLinkListR(li):
l = Node()
r = l # r指向尾节点
for num in li:
s = Node(num):
r. next = s
r = s # 重新指定尾节点
双链表
双链表中每个节点有两个指针:一个指向后面节点,一个指向前面节点。
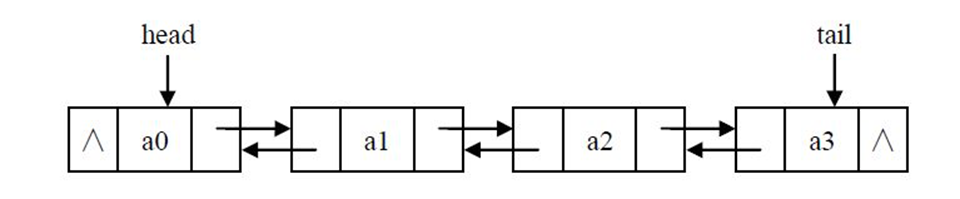
1、节点定义:
class Node( object ):
def __init__( self ,item = None ):
self .item = item # 记录当前值
self . next = None # 记录下一个值
self .prior = None # 记录前置的一个值
2、双链表节点的插入和删除
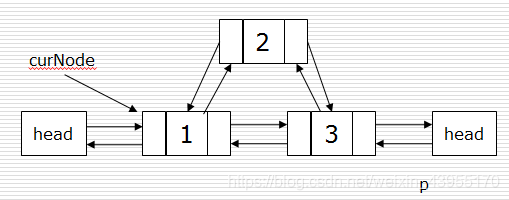
curNode = Node( 1 ) # 取一数据作为标志位
1)插入:
p = Node( 2 ) # 要插入的数 p. next = curNode. next # 指定插入数的next 是 当前数的next curNode. next .prior = p # 指定插入数的下一个数的 前置数为当前的数值 p.prior = curNode # 插入数的前置数为 标志位 curNode. next = p # 指定,标志位的next数是当前要插入的数
2)删除:
p = curNode. next # 标志位的下一个数,要删除的数 curNode. next = p. next # 将next指向下一个数 p. next .prior = curNode # 将要删除数的下一个数的前置数改为标志位 del p # 删除当前数
3、建立双链表
尾插法:
def createLinkListR(li):
l = Node()
r = l
for num in li:
s = Node(num)
r. next = s
s.prior = r
r = s
return l,r
单链表逆置

循环反转单链表。在循环的方法中,使用pre指向前一个节点,cur指向当前节点,每次把cur->next指向pre即可。
# 创建节点
class Node( object ):
def __init__( self ,item = None , next = None ):
self .item = item # 数据域
self . next = next # 指针域
# 循环逆置方法
def revLinkList(link):
if link is None or link. next is None :
return link
pre = link # 记录当前节点的值
cur = link. next # 记录下一节点的值
pre. next = None # 先将当前节点的next指向定为None
while cur: # 链表中一直有值
tmp = cur. next # 获取cur的下一个值,临时赋值给tmp
cur. next = pre # 将cur值指向pre
pre = cur # 重新指定
cur = tmp
return pre # 把当前值返回
#应用
link = Node( 1 , Node( 2 , Node( 3 , Node( 4 , Node( 5 , Node( 6 , Node( 7 , Node( 8 , Node( 9 )))))))))
r = revLinkList(link): # 链表逆置之后,得到的head值
while r:
print ( "{0}---->" . format (r.item)) # 输出逆置后的当前值
r = r. next # 获取下一个,重新赋给r,然后交给上边输出
列表的实现机制
Python 标准类型 list 就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。 允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时 list 对象的标识 id 不变,只能采用分离式实现技术。
在 Python 的官方实现中,list 就是一种采用分离式技术实现的动态顺序表。这就是为什么用 list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在 Python 的官方实现中,list 实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳 8 个元素的存储区;在执行插入操作(insert 或 append)时,如果元素存储区满就换一块 4 倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。
列表的实现可以是数组或者链表。列表是一种顺序表,顺序表一般是数组。列表是一个线性表,它允许用户在任何位置进行插入、删除、访问和替换元素。
列表的实现是基于数组或者基于链表结构,当使用列表迭代器的时候,双向链表结构比单链表结构更快。
Python 中的列表英文名是 list,因此很容易与 C 语言中的链表搞混了,因为在 C 语言中大家经常给链表命名为 list。事实上 CPython,也是我们常见的用 C 语言开发的 Python 解释器,Python 语言底层是 C 语言实现的)中的列表根本不是列表。在 CPython 中列表被实现为长度可变的数组。
从细节上看,Python 中的列表是由其他对象的引用组成的连续数组,指向这个数组的指针及其长度被保存在一个列表头结构中。这就意味着,每次添加或删除一个元素时,由引用组成的数组需要改变大小(重新分配)。幸运的是,Python在创建这些数组时采用了指数分配,所以并不是每次操作都要改变数组的大小。但是,也因为这个原因添加或者取出元素是平摊复杂度较低。不幸的是,在普通链表上“代价很小”的其他一些操作在 Python 中计算复杂度相对较高。
总的来说,Python中的列表是一个动态的顺序表,而顺序表大多是由数组实现的。
链表
链表是由许多相同数据类型的数据项按照特定的顺序排列而成的线性表。链表中的数据项在计算机的内存中的位置是不连续且随机的,然而列表是连续的。链表数据的插入和删除是很方便的,但数据的查找效率较低,不能像列表一样随机读取数据。
链表由一个一个的结点构成,每个结点由数据域和“指针域”组成,数据域存储数字,“指针域”指向下一个结点所在的内存地址。(因为Python 中没有指针这一概念的,这里的指针是一种指向)
class Node(object):
"""节点"""
def __init__(self, elem):
self.elem = elem
self.next = None
链表封装的一系列操作:
class SingleLinkList(object):
"""单链表"""
def __init__(self, node=None):
self.__head = node
def is_empty(self):
"""链表是否为空"""
return self.__head == None
def length(self):
"""链表长度"""
# cur游标,用来移动遍历节点
cur = self.__head
# count记录数量
count = 0
while cur != None:
count += 1
cur = cur.next
return count
def travel(self):
"""遍历整个链表"""
cur = self.__head
while cur != None:
print(cur.elem, end=" ")
cur = cur.next
print("")
def add(self, item):
"""链表头部添加元素,头插法"""
node = Node(item)
node.next = self.__head
self.__head = node
def append(self, item):
"""链表尾部添加元素, 尾插法"""
node = Node(item)
if self.is_empty():
self.__head = node
else:
cur = self.__head
while cur.next != None:
cur = cur.next
cur.next = node
def insert(self, pos, item):
"""指定位置添加元素
:param pos 从0开始
"""
if pos <= 0:
self.add(item)
elif pos > (self.length()-1):
self.append(item)
else:
pre = self.__head
count = 0
while count < (pos-1):
count += 1
pre = pre.next
# 当循环退出后,pre指向pos-1位置
node = Node(item)
node.next = pre.next
pre.next = node
def remove(self, item):
"""删除节点"""
cur = self.__head
pre = None
while cur != None:
if cur.elem == item:
# 先判断此结点是否是头节点
# 头节点
if cur == self.__head:
self.__head = cur.next
else:
pre.next = cur.next
break
else:
pre = cur
cur = cur.next
def search(self, item):
"""查找节点是否存在"""
cur = self.__head
while cur != None:
if cur.elem == item:
return True
else:
cur = cur.next
return False
链表与列表的差异
Python 中的 list(列表)并不是传统意义上的列表,传统的意义上的列表就是链表,不同地方在于链表在数据存储方面更加的自由,其带有指示下一个结点未知的指向,可以随意的存储数据。而列表则只能分配在一段连续的存储空间里,且是作为一个整体,这就大大限制了数据的变更操作,但其在进行一些基础简单的操作时,时间复杂度极低。
list(列表):动态的顺序表
链表:存储地址分散的,需要“指针”指向的线性表
链表插入删除效率极高,达到O(1)。对于不需要搜索但变动频繁且无法预知数量上限的数据,比如内存池、操作系统的进程管理、网络通信协议栈的 trunk 管理等。甚至就连很多脚本语言都有内置的链表、字典等基础数据结构支持。
列表是一个线性的集合,它允许用户在任何位置插入、删除、访问和替换元素。
列表实现是基于数组或基于链表结构的。当使用列表迭代器的时候,双链表结构比单链表结构更快。
有序的列表是元素总是按照升序或者降序排列的元素。
实现细节
python中的列表的英文名是list,因此很容易和其它语言(C++, Java等)标准库中常见的链表混淆。事实上CPython的列表根本不是列表(可能换成英文理解起来容易些:python中的list不是list)。在CPython中,列表被实现为长度可变的数组。
可参考《Python高级编程(第2版)》
从细节上看,Python中的列表是由对其它对象的引用组成的连续数组。指向这个数组的指针及其长度被保存在一个列表头结构中。这意味着,每次添加或删除一个元素时,由引用组成的数组需要该标大小(重新分配)。幸运的是,Python在创建这些数组时采用了指数分配,所以并不是每次操作都需要改变数组的大小。但是,也因为这个原因添加或取出元素的平摊复杂度较低。
不幸的是,在普通链表上“代价很小”的其它一些操作在Python中计算复杂度相对过高。
利用 list.insert(i,item) 方法在任意位置插入一个元素——复杂度O(N)
利用 list.pop(i) 或 list.remove(value) 删除一个元素——复杂度O(N)
列表的算法效率
可以采用时间复杂度来衡量:
index() O(1)
append O(1)
pop() O(1)
pop(i) O(n)
insert(i,item) O(n)
del operator O(n)
iteration O(n)
contains(in) O(n)
get slice[x:y] O(k)
del slice O(n)
set slice O(n+k)
reverse O(n)
concatenate O(k)
sort O(nlogn)
multiply O(nk)
O括号里面的值越大代表效率越低
到此这篇关于Python 列表与链表的区别详解的文章就介绍到这了,更多相关Python 列表与链表区别内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章来自:http://www.yidunidc.com/gfcdn.html 欢迎留下您的宝贵建议】