
python简单爬虫--get方式详解
目录
- 环境准备
- 进行爬虫
- 参考
- 总结
简单爬虫可以划分为get、post格式。其中,get是单方面的获取资源,而post存在交互,如翻译中需要文字输入。本文主要描述简单的get爬虫。
环境准备
安装第三方库
pip install requests pip install bs4 pip install lxml
进行爬虫
1.获取网页数据。
import requests from bs4 import BeautifulSoup url = "https://cn.bing.com/search?q=爬虫CSDN&qs=n&form=QBRE&sp=-1&pq=爬虫csdn&sc=5-6&sk=&cvid=0B13B88D8F444A0182A4A6C36E463179/" response = requests.get(self.url)
2.解析网页数据
soup = BeautifulSoup(response.text, 'lxml')
3.选取目标数据。此处key 依据源代码目标标题的位置确定。首先进入开发者模式,后查看目标在html中的位置,右击选择“复制selector”,见下图。
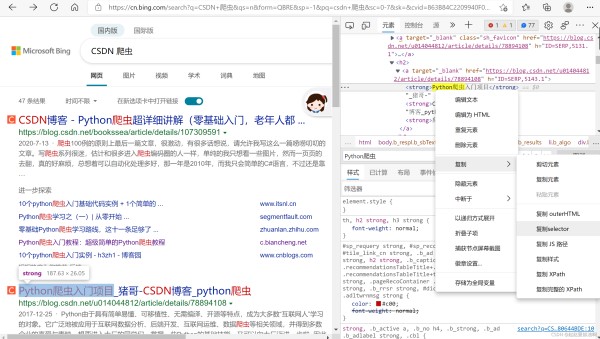
key = "#b_results > li > div.b_title > h2 > a" soup.select(key)
4.清洗数据
result = {}
for i, item in enumerate(data):
result.update({
f'title_{i}': item.get_text(),
f'url_{i}': item.get('href')
})
print(result)
参考
链接:https://www.jb51.net/article/152560.htm
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注hwidc的更多内容!
【本文由:日本服务器 欢迎转载】