
如何基于opencv实现简单的数字识别
目录
- 前言
- 要解决的问题
- 解决问题的思路
- 总结
前言
由于自己学识尚浅,不能用python深度学习来识别这里的数字,所以就完全采用opencv来识别数字,然后在这里分享、记录一下自己在学习过程中的一些所见所得和所想

要解决的问题
这是一个要识别的数字,我这里首先是对图像进行一个ROI的提取,提取结果就仅仅剩下数字,把其他的一些无关紧要的要素排除在外,

这是ROI图片,我们要做的就是识别出该照片中的数字,
解决问题的思路
1、先把这个图片中的数字分割,分割成为5张小图片,每张图片包含一个数字,为啥要分割呢?因为我们没办法让计算机知道这个数字是多少,所以只能根据特征,让计算机去识别特征,然后每一个特征对应一个值,首先贴出分割图片的程序,然后在程序下方会有一段思路解释
#include <opencv2/core/core.hpp>
#include <opencv.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <ctime>
using namespace std ;
using namespace cv;
#include <map>
Mat src_threshold;
Mat src_dil;
int sunImage(Mat &image);
vector<Mat>ROI_image;//待测图片
int main()
{
clock_t start ,finish;
start=clock();
Mat src;
src=imread("D:\\vspic\\picture\\number6.jpg");
resize(src,src,Size(src.cols/7,src.rows/7));
imshow("src",src);
Mat src_gray;
cvtColor(src,src_gray,COLOR_BGR2GRAY);
//imshow("gsrc_ray",src_gray);
Mat src_blur;
blur(src_gray,src_blur,Size(9,9));
//GaussianBlur(src_gray,src_blur,Size(11,11),1,1);
Mat src_threshold;
threshold(src_blur,src_threshold,150,255,THRESH_OTSU);
//imshow("src_threshold",src_threshold);
Mat src_canny;
Canny(src_threshold,src_canny,125,255,3);
//imshow("src_canny",src_canny);
vector<vector<Point>>contours_src;
vector<Vec4i>hierarchy_src(contours_src.size());
findContours(src_canny,contours_src,hierarchy_src,RETR_EXTERNAL,CHAIN_APPROX_NONE);
Rect rect_s;
Rect choose_rect;
for (size_t i=0;i<contours_src.size();i++)
{
rect_s=boundingRect(contours_src[i]);
double width=rect_s.width;
double height= rect_s.height;
double bizhi=width/height;
if (bizhi>1.5&&height>50)
{
/*rectangle(src,rect_s.tl(),rect_s.br(),Scalar(255,255,255),1,1,0);*/
choose_rect=Rect(rect_s.x+20,rect_s.y+30,rect_s.x-30,rect_s.y-108);
}
}
Mat roi;
roi=src(choose_rect);
//imshow("src_",roi);
Mat img =roi;
Mat gray_img;
// 生成灰度图像
cvtColor(img, gray_img, CV_BGR2GRAY);
// 高斯模糊
Mat img_gau;
GaussianBlur(gray_img, img_gau, Size(3, 3), 0, 0);
// 阈值分割
Mat img_seg;
threshold(img_gau, img_seg, 0, 255, THRESH_BINARY + THRESH_OTSU);
Mat element;
element=getStructuringElement(MORPH_RECT,Size(8,8));
erode(img_seg,src_dil,element);
//imshow("src_dil",src_dil);
// 边缘检测,提取轮廓
Mat img_canny;
Canny(src_dil, img_canny, 200, 100);
//imshow("canny",img_canny);
vector<vector<Point>> contours;
vector<Vec4i> hierarchy(contours.size());
findContours(img_canny, contours, hierarchy, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE, Point());//寻找轮廓
int size = (int)(contours.size());//轮廓的数量
//cout<<size<<endl;6个
// 保存符号边框的序号
vector<int> num_order;//定义一个整型int容器
map<int, int> num_map;//容器,需要关键字和模板对象两个模板参数,此处定义一个int作为索引,并拥有相关连的指向int的指针
for (int i = 0; i < size; i++)
{
// 获取边框数据
Rect number_rect = boundingRect(contours[i]);
int width = number_rect.width;//获取矩形的宽
int height = number_rect.height;//获取矩形的高
// 去除较小的干扰边框,筛选出合适的区域
if (width > img.cols/20 )
{
rectangle(img,number_rect.tl(),number_rect.br(),Scalar(255,255,255),1,1,0);//绘制矩形
imshow("img",img);//显示矩形框
num_order.push_back(number_rect.x);//把矩形的x坐标放入number_order容器中,将一个新的元素添加到vector的最后面,
//位置为当前元素的下一个元素
num_map[number_rect.x] = i;//向map中存入键值对,number_rect.x是关键字,i是值
/*把矩形框的x坐标与对应的i值一起放入map容器中,形成一一对应的键值对
*/
}
}
// 按符号顺序提取
sort(num_order.begin(), num_order.end());/*把number_order容器中的内容按照从小到大的顺序排列,这里面是X的坐标*/
for (int i = 0; i < num_order.size(); i++) {
Rect number_rect = boundingRect(contours[num_map.find(num_order[i])->second]);//num_order里面放的是坐标
//cout<<"num_map的值是:"<<num_map.find(num_order[i])->second<<endl;
Rect choose_rect(number_rect.x, 0, number_rect.width, img.rows);//矩形左上角x,y的坐标以及矩形的宽和高
Mat number_img = img(choose_rect);
resize(number_img,number_img,Size(30,100));//归一化尺寸
ROI_image.push_back(number_img);//保存为待测图片
//imshow("number" + to_string(i), number_img);
char name[50];
sprintf_s(name,"D:\\vs2012\\model\\%d.jpg",i);//保存模板
imwrite(name, number_img);
}
cout<<"图片分割完毕"<<endl;
//加载模板
vector<Mat>temptImage;//存放模板
for (int i=0;i<4;i++)
{
char name[50];
sprintf_s(name,"D:\\vs2012\\model\\%d.jpg",i);
Mat temp;
temp=imread(name);
//cout<<"加载模板图片通道数:"<<temp.channels()<<endl;
temptImage.push_back(temp);
}
vector<int>seq;//存放顺序结果
for (int i=0;i<ROI_image.size();i++)
{
Mat subImage;
int sum=0;
int min=50000;
int seq_min=0;//记录最小的和对应的数字
for (int j=0;j<4;j++)
{
absdiff(ROI_image[i],temptImage[j],subImage);//待测图片像素减去模板图片像素
sum=sunImage(subImage);//统计像素和
if (sum<min)
{
min=sum;
seq_min=j;
}
sum=0;
}
seq.push_back(seq_min);
}
cout<<"输出数字匹配结果:";//endl是换行的意思
for (int i=0;i<seq.size();i++)//输出结果,小数点固定在第3位
{
cout<<seq[i];
if (i==1)
{
cout<<".";
}
}
finish=clock();
double all_time=double(finish-start)/CLOCKS_PER_SEC;
/*cout<<"运行总时间是:"<<all_time<<endl;*/
waitKey(0);
return 0;
}
//计算像素和
int sunImage(Mat &image)
{
int sum=0;
for (int i=0;i<image.cols;i++)
{
for (int j=0;j<image.rows;j++)
{
sum+=image.at<uchar>(j,i);
}
}
return sum;
}
整体思路是这样子的:0-9这10个数字也都是已经被分割好的,并且保存好了,也就是模板,然后我们把待测的图片也分割掉,然后从0-9模板文件夹中去读取模板图片,让待测的分割完毕的图片去和10个模板逐个相减,然后去统计他们相减后的像素和,如果这个在这10个中最低,那么他们就是同一个数字,然后输出值就可以了,分割后的大概是这样

上边是第一种方法,然后还有第二种,是穿针引线的方法,是根据晶体管数字特征来识别的
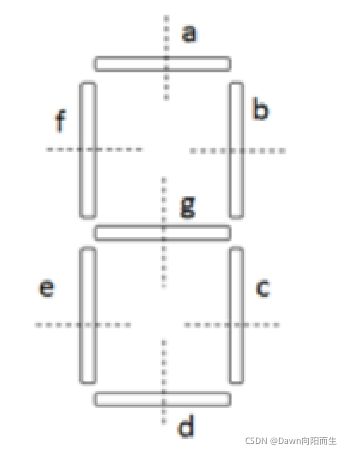
这是晶体管数字的特征,每个0-9每个数字都是不一样的,我们下一篇文章再做详细的介绍
总结
到此这篇关于如何基于opencv实现简单的数字识别的文章就介绍到这了,更多相关opencv实现数字识别内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章来源:新加坡服务 欢迎留下您的宝贵建议】