
Java必备知识之位运算及常见进制解读
目录
- 常见几种进制?
- Java八种按位运算?
- HashMap添加元素四步曲用到的位运算?
- 前奏:HashMap如何添加一个元素?
- 第一步曲
- 第二步曲
- 第三步曲
- 第四步曲
- 终曲:为什么HashMap底层源码用这么多位运算?
您好,我是贾斯汀,欢迎又进来学习啦!

【学习背景】
学习Java的小伙伴,都知道想要提升个人技术水平,阅读JDK源码少不了,但是说实话还是有些难度的,底层源码实现的原理离不开各种常用的数据结构和算法,很多时候还会用到各种位运算,比如面试必问和工作写烂透了的HashMap,就一个put(key,value)添加元素的底层实现,就用到了各种位运算知识,不对位运算略知一二,你还真读不懂它的源码,所以本文主要对Java中的几种位运算以及常见进制的说明,还会以HashMap底层实现添加元素四部曲展开说明,希望能提高提升自己对源码的理解,也希望能帮助到有需要的小伙伴~
进入正文~
常见几种进制?
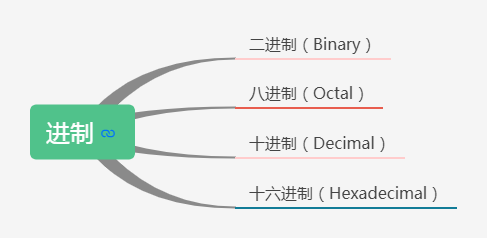
- 二进制(Binary)
数值范围0,1,满2进1
以0b或0B开头
bit比特是计算机最小存储单元,1个bit占用1个二进制位即0或1
1个byte字节有8个bit即占用8个二进制位
int整型4字节占用32个二进制位
二进制左半部分表示高位,右半部分为低位
二进制最高位为0表示正数,最高位为1表示负数
二进制原码取反得到反码,反码补1得到补码,负数使用补码表示
- 八进制(Octal)
数值范围0-7,满8进1
以数字0开头表示
- 十进制(Decimal)
数值范围0-9 ,满10进1
日常阿拉伯数字即十进制
- 十六进制(Hexadecimal)
数值范围0-9及A-F,满16进1
以0x或0X开头表示。 此处的A-F不区分大小写
Java八种按位运算?
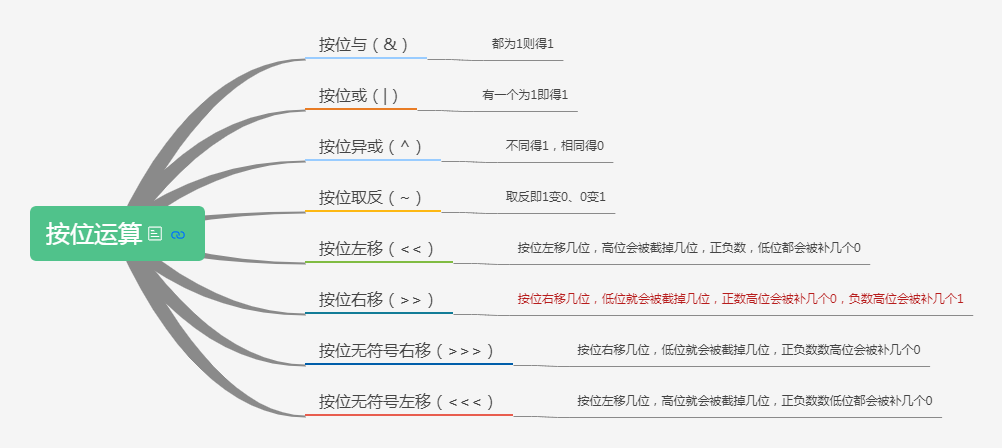
- 按位与(&)
都为1则得1
- 按位或(|)
有一个为1即得1
- 按位异或(^)
不同得1,相同得0
- 按位取反(~)
取反即1变0、0变1
- 按位左移(<<)
按位左移几位,高位会被截掉几位,正负数,低位都会被补几个0
- 按位右移(>>)
按位右移几位,低位就会被截掉几位,正数高位会被补几个0,负数高位会被补几个1
- 按位无符号右移(>>>)
按位右移几位,低位就会被截掉几位,正负数数高位会被补几个0
- 按位无符号左移(<<<)
按位左移几位,高位就会被截掉几位,正负数数低位都会被补几个0
HashMap添加元素四步曲用到的位运算?
前奏:HashMap如何添加一个元素?
HashMap底层数据结构是数组+链表,通过put(K key, V value)方法添加元素,底层四步曲如下:
- 第一步曲:根据key得到hashCode值
- 第二步曲:根据hashCode值计算出hash值
- 第三步曲:根据hash值计算出元素(key/value)最终要放在哪个数组index下标
- 第四步曲:最后根据元素(key/value)新建节点并保存到指定数组index下标位置
Java HashMap添加元素的示例代码:
HashMap<Object, Object> map = new HashMap<>();
map.put("name","Justin");
HashMap底层put(key,value)方法源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
接下来将解读底层源码用到哪些位运算,有什么奥妙之处
第一步曲
根据key得到hashCode值
可以看到hash值计算的过程就用到了^(异或)和>>>(无符号右移)两种位运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里key是字符串"name",String重写了计算字符串hashCode值的hashCode()方法,源码如下:
计算得到hashCode值为3373707
第二步曲
根据hashCode值计算出hash值
(h = key.hashCode()) ^ (h >>> 16) 即 (3373707) ^ (3373707 >>> 16)
3373707二进制表达
0000000001100110111101010001011
h >>> 16二进制表达
00000000000000000000000000110011
根据^异或运算原理即不同得1,相同得0得到3373707 ^ (3373707 >>>16)二进制结果为:
0000000001100110111101010111000
进制在线转换:http://tools.jb51.net/transcoding/hexconvert
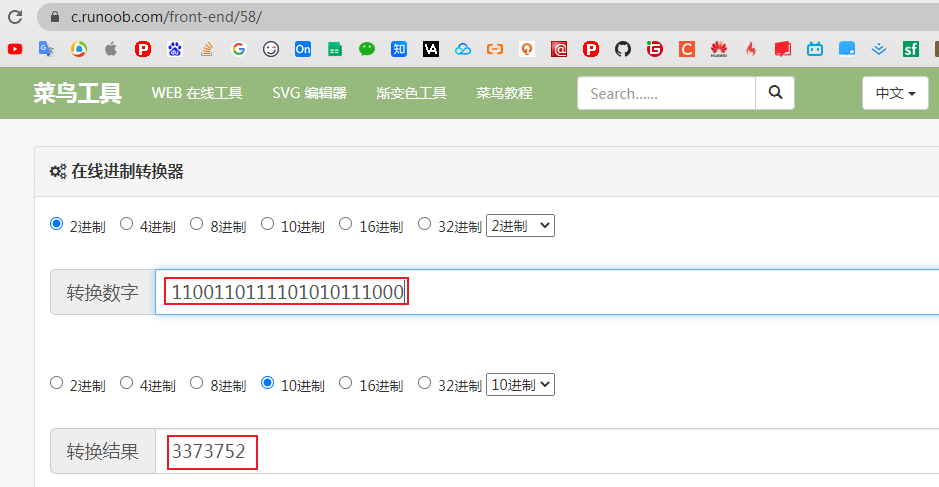
即计算key的hash值得到3373752,断点往后查看hash值刚好也是这个值
第三步曲
根据hash值计算出元素(key/value)最终要放在哪个数组index下标
公式:i = (n - 1) & hash
这里就用到了&按位与运算(都为1则得1)
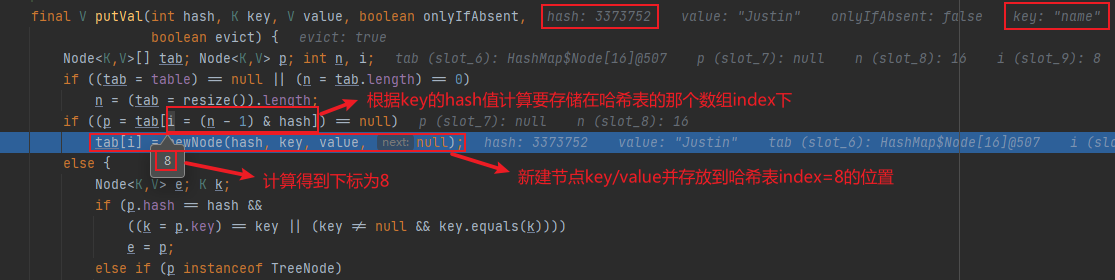
公式(n - 1) & hash 的奥妙之处在于,n表示HashMap中的数组容量大小,并且刚好是16,32,64…2的次方,这种情况其实是等效于 hash % n 取模,计算出的数组index下标值一样,还能够保证不会数组下标越界
但是HashMap这里没有使用%取模,因为hash值是int整型即十进制数值,使用%取模会先将内存数据转成十进制再进行运算,多了这部分的性能开销,因此效率比较低
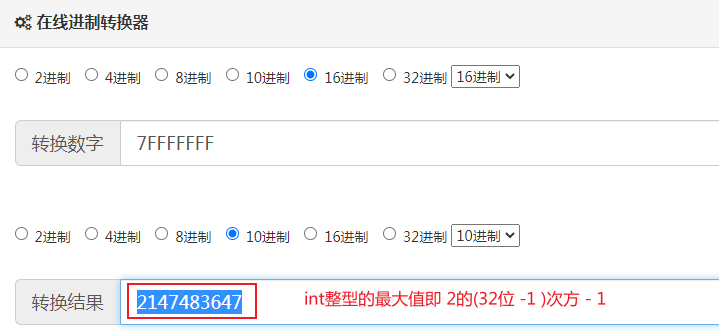
HashTable底层倒是用的%取模,hash值与十六进制0x7FFFFFFF做按位与运算目的是为了保证hash值始终是正数
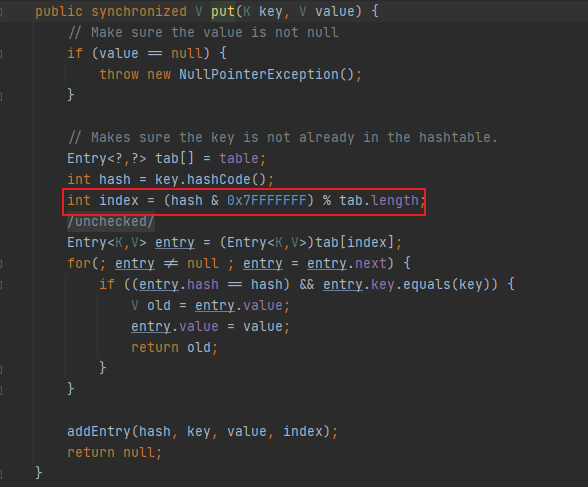
有的小伙伴可能会问了,使用%取模计算,那这里为啥HashTable还在用,我想说的是其实也可以优化,只不过HashTable本身就是主打synchronized线程安全,也就不考虑优化%取模为位运算了
第四步曲
最后根据元素(key/value)新建节点并保存到指定数组index下标位置
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
终曲:为什么HashMap底层源码用这么多位运算?
关于位运算的使用,文中在介绍第三步曲时,也提到了HashMap计算数组下标使用%取模和位运算的问题,使用于位运算的奥妙之处在直接从内存读取数据进行计算,不需要转成十进制,如果使用%取模需要先转成十进制,有性能开销,效率比较低
HashMap底层除了文中提到的^按位异或、>>>无符号右移、&按位与位运算,其实在HashMap的扩容机制resize()中,还用到了<<左移运算
oldCap << 1
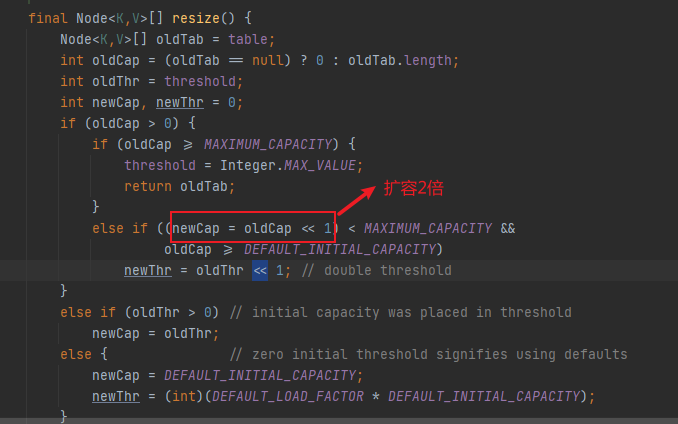
这里oldCap << 1刚好是两倍,可以总结的说一个数与n进行左移运算,结果为这个数乘以2的n次方
oldCap << 1 等值 oldCap = oldCap * (2的n次方)
同理,一个数与n进行右移运算结果为这个数除以2的n次方
oldCap >> 1 等值 oldCap = oldCap / (2的n次方)
**
到此这篇关于Java必备知识之位运算及常见进制解读的文章就介绍到这了,更多相关Java 位运算内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!
【文章出处http://www.nextecloud.cn/kt.html欢迎转载】