
Pandas数据分析之批量拆分/合并Excel
目录
- 前言
- 一、假造数据
- 二、程序演示
- 1、将一个大Excel等份拆成多个Excel
- 2、合并多个小Excel到一个大Excel
- 总结
前言
笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中数据的合并(concat和append)
将一个大的Excel等份拆成多个Excel将多个小Excel合并成一个大的Excel并且标记来源
一、假造数据
work_dir="./datas"
splits_dir=f"{work_dir}/splits"
import os
if not os.path.exists(splits_dir):
os.mkdir(splits_dir)
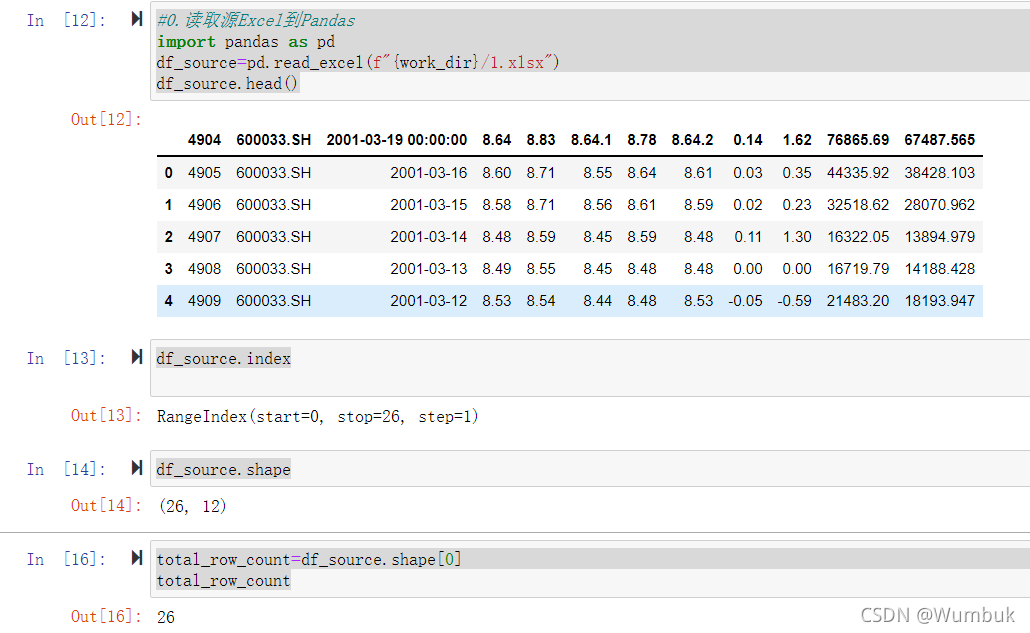
#0.读取源Excel到Pandas
import pandas as pd
df_source=pd.read_excel(f"{work_dir}/1.xlsx")
df_source.head()
df_source.index
df_source.shape
total_row_count=df_source.shape[0]
total_row_count
二、程序演示
1、将一个大Excel等份拆成多个Excel
- 使用df.iloc方法,将一个大的dataframe,拆分成多个小的dataframe
- 将使用dataframe.to_excel保存每个小的Excel
#1.计算拆分后的每个excel的行数
#这个大excel,会拆分给这几个人
user_names=['xiao_shuai',"xiao_wang","xiao_ming","xiao_lei","xiao_bo","xiao_hong"]
#每个人的人数数目
split_size=total_row_count//len(user_names)
if total_row_count%len(user_names)!=0:
split_size+=1
split_size
#拆分成多个dataframe
df_subs=[]
for idx,user_name in enumerate(user_names):
#iloc的开始索引
begin=idx*split_size
#iloc的结束索引
end=begin+split_size
#实现df按照iloc拆分
df_sub=df_source.iloc[begin:end]
#将每个子df存入到列表
df_subs.append((idx,user_name,df_sub))
#3. 将每个dataframe存入到excel
for idx,user_name,df_sub in df_subs:
file_name=f"{splits_dir}/articles_{idx}_{user_name}.xlsx"
df_sub.to_excel(file_name,index=False)
2、合并多个小Excel到一个大Excel
- 遍历文件夹,得到要合并的Excel文件列表
- 分别读取到dataframe,给每个df添加一列用于标记来源
- 使用pd.concat进行df批量合并
- 将合并后的dataframe输出到excel
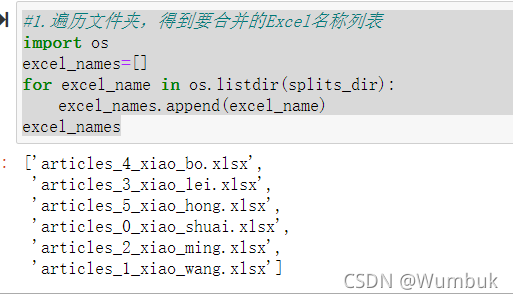
#1.遍历文件夹,得到要合并的Excel名称列表
import os
excel_names=[]
for excel_name in os.listdir(splits_dir):
excel_names.append(excel_name)
excel_names
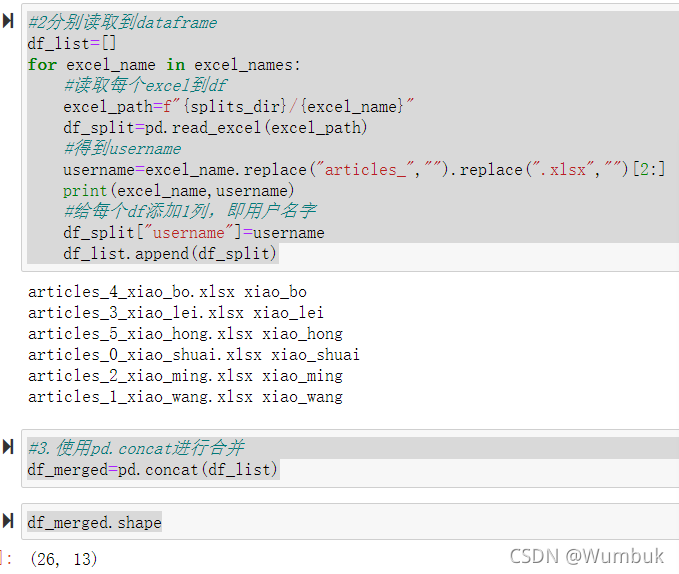
#2分别读取到dataframe
df_list=[]
for excel_name in excel_names:
#读取每个excel到df
excel_path=f"{splits_dir}/{excel_name}"
df_split=pd.read_excel(excel_path)
#得到username
username=excel_name.replace("articles_","").replace(".xlsx","")[2:]
print(excel_name,username)
#给每个df添加1列,即用户名字
df_split["username"]=username
df_list.append(df_split)
#3.使用pd.concat进行合并
df_merged=pd.concat(df_list)
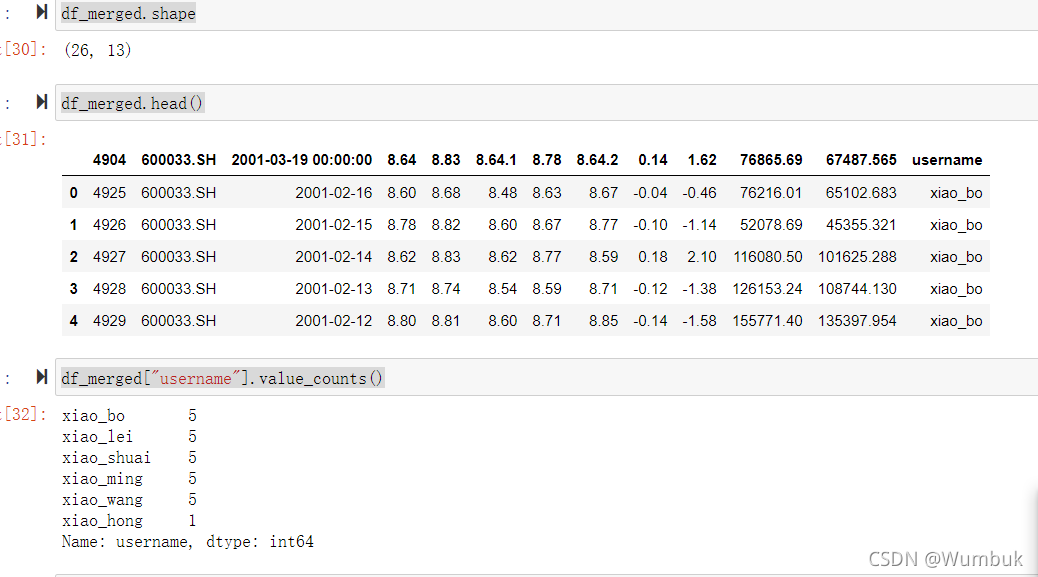
df_merged.shape
df_merged.head()
df_merged["username"].value_counts()
#4.将合并后的dataframe输出到excel
df_merged.to_excel(f"{work_dir}/result_merged.xlsx",index=False)
总结
这就是pandas的DataFrame和存储文件之间转换的基本用法了,希望可以帮助到你。
到此这篇关于Pandas数据分析之批量拆分/合并Excel的文章就介绍到这了,更多相关Pandas批量拆分合并Excel内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章由:韩国高防服务器 提供,感谢支持】