
Python机器学习入门(一)序章
目录
- 前言
- 写在前面
- 1.什么是机器学习?
- 1.1 监督学习
- 1.2无监督学习
- 2.Python中的机器学习
- 3.必须环境安装
- Anacodna安装
- 总结
前言
每一次变革都由技术驱动。纵观人类历史,上古时代,人类从采集狩猎社会,进化为农业社会;由农业社会进入到工业社会;从工业社会到现在信息社会。每一次变革,都由新技术引导。
在历次的技术革命中,一个人、一家企业,甚至一个国家,可以选择的道路只有两条:要么加入时代的变革,勇立潮头;要么徘徊观望,抱憾终生。
要想成为时代弄潮儿,就要积极拥抱这次智能变革,就要掌握在未来社会不会被淘汰的技能,强大自己,为社会、为国家贡献自己的力量。而在以大数据为基石的智能社会,我们就要积极掌握前沿技术,机器学习就是信息时代人工智能领域核心技术之一。
像个优秀的工程师一样使用机器学习,而不要像个机器学习专家一样使用机器学习方法。
写在前面
机器学习中算法众多,原理复杂,需要大量知识储备才能真正理解,也不需要完全理解,在今后的学习过程中逐渐积累,自然会逐渐掌握。因此本系列不会着重介绍算法原理,而侧重于如何“像一个优秀的工程师一样使用机器学习”。
1.什么是机器学习?
机器学习(Machine Learning,ML)是一门多领域的交叉学科,涉及概率论、统计学、线性代数、算法等多门学科。它专门研究如何使计算机模拟和学习人的行为,以获取新的知识和技能,重新组织已有的知识结构使之不断完善自身的性能,
机器学习拥有十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别等。
机器学习算法可分为两大类:监督学习和无监督学习。
下图是机器学习相关概念的思维导图:
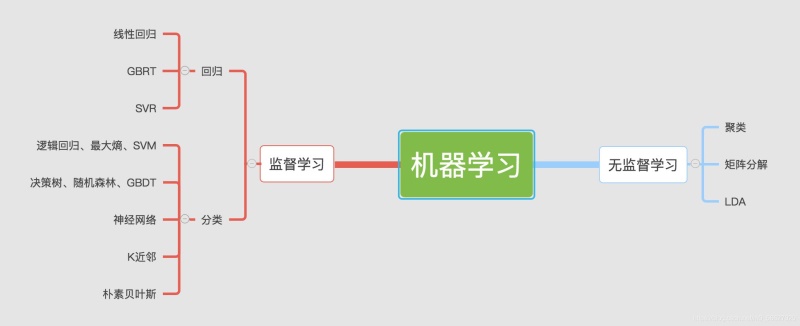
1.1 监督学习
监督学习即在机器学习过程中提供对错指示。一般是在数据组中包含最终结果(0,1),通过最终结果来让机器自己减小误差。
这一类学习主要应用于分类和回归(Regression & Classify)。监督学习从给定的训练数据集中学习出一个目标函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入和输出(只要有标签的均可认为是监督学习),也可以说包括特征和目标,训练集中的目标是认为标注的。
常见的监督学习算法包括回归分析和统计分类。
1.2无监督学习
无监督学习又称为归纳性学习(Clustering),利用K方式(KMean)建立中心(Centriole),通过循环和递减运算(Iteration&Descent)来减小误差,达到分类的目的。
2.Python中的机器学习
本文将通过项目来介绍基于Python的生态环境如何完成机器学习的相关工作。
利用机器学习的预测模型来解决问题共有六个基本步骤:
- 定义问题:研究和提炼问题的特征,以便我们采用相应的思路和方法来解决问题。
- 数据理解:通过统计性描述和可视化方法来分析现有的数据。
- 数据准备:对数据进行格式化,以便构建预测模型。
- 评估算法:利用测试集来评估算法模型,并选取一部分代表数据进行分析,以改善模型。
- 优化模型:通过调参和集成算法来提升结果的准确度。
- 结果部署:完成模型,并执行模型来预测结果和展示。
这也是本文写作的顺序。阅读完本文,读者能够基本了解机器学习的基本步骤、实现方法,以便在自己的项目中利用机器学习来解决问题。
3.必须环境安装
机器学习需要用到的相关模块包括SciPy,NumPy,Matplotlib,Pandas,Scikit-learn。
SciPy是在数学运算、科学和工程学方面被广泛应用的Python类库。它包括统计、优化、整合、线性代数、傅里叶变换、信号和图像处理、常微分方程求解器等,被广泛运用在机器学习的项目中。
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持高维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
Matplotlib是Python中最著名的2D绘图库,十分适合交互式地绘图,也可方便地将它作为绘图控件,嵌入GUI应用程序中。
Pandas 是Python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
Scikit-learn (sklearn) 是基于 Python 语言的机器学习工具,可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。
Anacodna安装
Anaconda 个人版是一个免费、易于安装的包管理器、环境管理器和 Python 发行版,包含 1,500 多个开源包,并提供免费社区支持。其中的虚拟环境真的非常Nice,可以方便地针对不同项目安装不同模块。
安装Anaconda时会自动地安装机器学习需要地所有库,无需再通过Pip逐个安装。
Anaconda的安装十分简单,但Anaconda官网安装非常慢,推荐到清华镜像下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
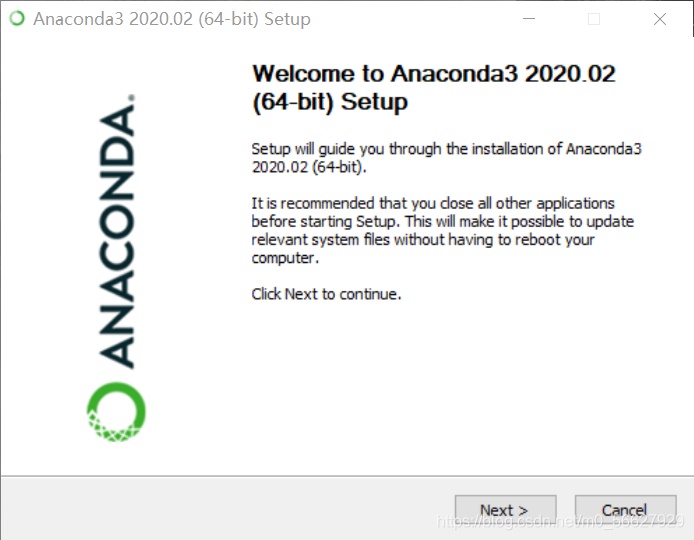
next
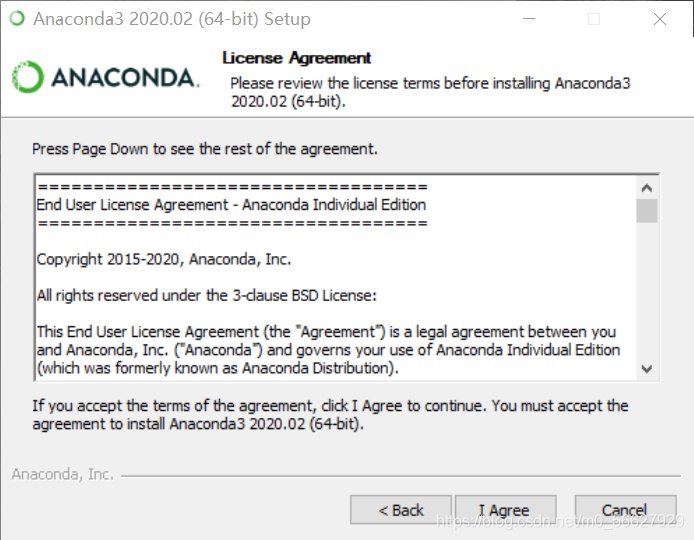
I Agree
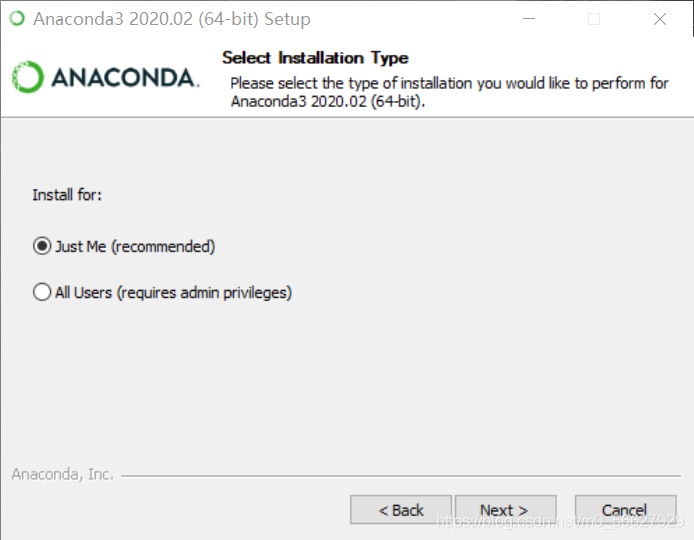
Just Me
更改安装路径到其他盘
勾选Register Anaconda3 as my default Python3.7,不推荐勾选第一个
点击Install
安装完成之后可以使用以下命令检验是否安装成功:
import scipy
import numpy
import matplotlib
import pandas
import sklearn
print('scipy:{}'.format(scipy.__version__))
print('numpy:{}'.format(numpy.__version__))
print('matplotlib:{}'.format(matplotlib.__version__))
print('pandas:{}'.format(pandas.__version__))
print('sklearn:{}'.format(sklearn.__version__))
结果如下:
scipy:1.4.1
numpy:1.21.0
matplotlib:3.4.2
pandas:1.0.1
sklearn:0.22.1
总结
到此为止,我们已经了解了机器学习的基本概念并完成了环境的安装,接下来将完善数据理解、数据准备、选择模型、优化模型、结果部署以及项目实战。
到此这篇关于Python机器学习入门(一)序章的文章就介绍到这了,更多相关Python机器学习内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章出处:外国服务器】