
总结分析python数据化运营关联规则
目录
- 内容介绍
- 一般应用场景
- 关联规则实现
- 关联规则应用举例
内容介绍
以 Python 使用 关联规则 简单举例应用关联规则分析。
关联规则 也被称为购物篮分析,用于分析数据集各项之间的关联关系。
一般应用场景
关联规则分析:最早的案例啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。
后来也引申到不同的应用场景,分析变量与变量之间的关系情况分析。总体来说分析的都是类别变量。
关联规则实现
import pandas as pd
from apriori_new import * #导入自行编写的apriori函数
import time #导入时间库用来计算用时
import re
import random
import pandas as pd
# 自定义关联规则算法
def connect_string(x, ms):
x = list(map(lambda i: sorted(i.split(ms)), x))
l = len(x[0])
r = []
# 生成二项集
for i in range(len(x)):
for j in range(i, len(x)):
# if x[i][l-1] != x[j][l-1]:
if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][
l - 1]: # 判断数字和字母异同,初次取字母数字不全相同(即不同症状(字母),或同一证型程度不同(数字))
r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]]))
return r
# 寻找关联规则的函数
def find_rule(d, support, confidence, ms=u'--'):
result = pd.DataFrame(index=['support', 'confidence']) # 定义输出结果
support_series = 1.0 * d.sum() / len(d) # 支持度序列
column = list(support_series[support_series > support].index) # 初步根据支持度筛选,符合条件支持度,共 276个index证型
k = 0
while len(column) > 1: # 随着项集元素增多 可计算的column(满足条件支持度的index)会被穷尽,随着证型增多,之间的关系会越来越不明显,(同时发生可能性是小概率了)
k = k + 1
print(u'\n正在进行第%s次搜索...' % k)
column = connect_string(column, ms)
print(u'数目:%s...' % len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only=True) # 新一批支持度的计算函数
len(d)
# 创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
# 依次对column每个元素(如[['A1', 'A2'], ['A1', 'A3']]中的['A1', 'A2'])运算,计算data_model_中对应该行的乘积,930个,若['A1', 'A2']二者同时发生为1则此行积为1
d_2 = pd.DataFrame(list(map(sf, column)),index=[ms.join(i) for i in column]).T # list(map(sf,column)) 276X930 index 276
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d) # 计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) # 新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: # 遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms) # 由'A1--B1' 转化为 ['A1', 'B1']
for j in range(len(i)): #
column2.append(i[:j] + i[j + 1:] + i[j:j + 1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) # 定义置信度序列
for i in column2: # 计算置信度序列 如i为['B1', 'A1']
# i置信度计算:i的支持度除以第一个证型的支持度,表示第一个发生第二个发生的概率
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])]
for i in cofidence_series[cofidence_series > confidence].index: # 置信度筛选
result[i] = 0.0 # B1--A1 0.330409 A1--B1 0.470833,绝大部分是要剔除掉的,初次全剔除
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(by=['confidence', 'support'],ascending=False) # 结果整理,输出,先按confidence升序,再在confidence内部按support升序,默认升序,此处降序
return result
关联规则应用举例
sku_list = [
'0000001','0000002','0000003','0000004','0000005',
'0000006','0000007','0000008','0000009','0000010',
'0000011','0000012','0000013','0000014','0000015',
'0000016','0000017','0000018','0000019','0000020',
'A0000001','A0000002','A0000003','A0000004','A0000005',
'A0000006','A0000007','A0000008','A0000009','A0000010',
'A0000011','A0000012','A0000013','A0000014','A0000015',
'A0000016','A0000017','A0000018','A0000019','A0000020',
]
# 随机抽取数据生成列表
mat = [ random.sample(sku_list, random.randint(2,5)) for i in range(100)]
data = pd.DataFrame(mat,columns=["A","B","C","D","E"])
data = pd.get_dummies(data) # 转换类别变量矩阵
data = data.fillna(0)
- 支持度:表示项集{X,Y}在总项集里出现的概率。
- 置信度:表示在先决条件X发生的情况下,由关联规则”X→Y“推出Y的概率。表示在发生X的项集中,同时会发生Y的可能性,即X和Y同时发生的个数占仅仅X发生个数的比例。
support = 0.01 #最小支持度 confidence = 0.05 #最小置信度 ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符 start = time.clock() #计时开始 print(u'\n开始搜索关联规则...') print(find_rule(data, support, confidence, ms)) end = time.clock() #计时结束 print(u'\n搜索完成,用时:%0.2f秒' %(end-start))
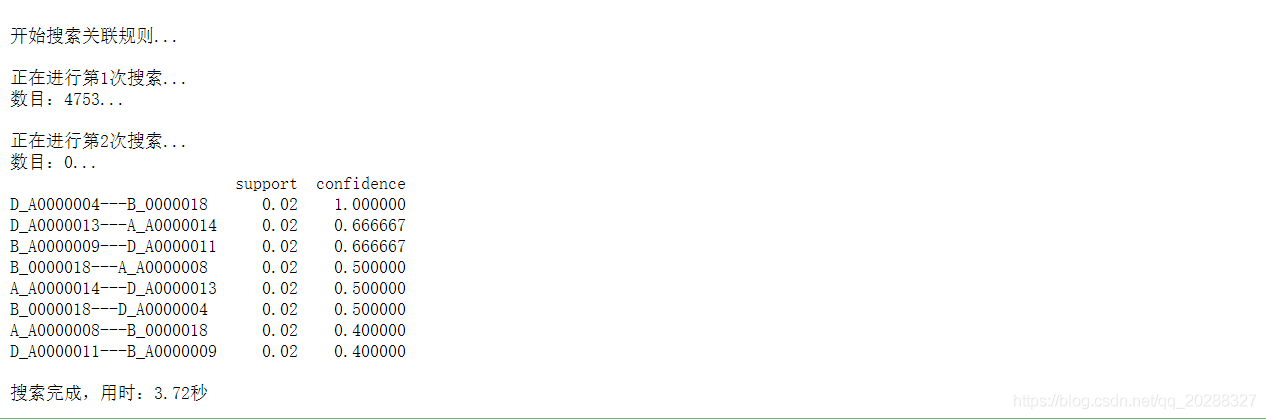
以上就是总结分析python数据化运营关联规则的详细内容,更多关于python数据化运营关联规则的资料请关注hwidc其它相关文章!
【原URL http://www.yidunidc.com/jap.html 请说明出处】