
一篇文章带你了解python正则表达式的正确用法
目录
- 正则表达式的介绍
- re模块
- 匹配单个字符
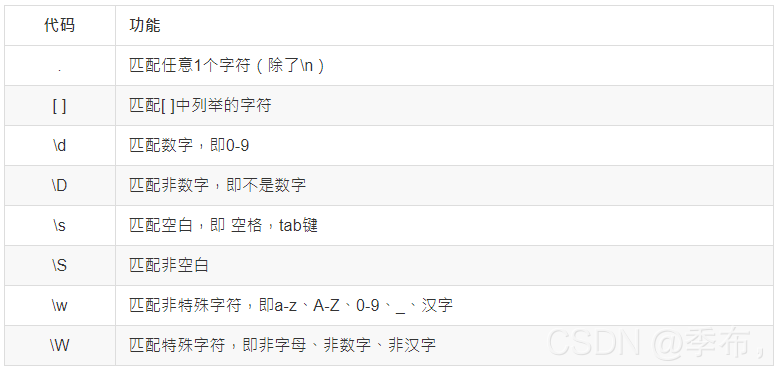
- 1.匹配任意一个字符
- 2.匹配[ ]中列举的字符
- 3.\d匹配数字,即0-9
- 4.\D匹配非数字,即不是数字
- 5.\s匹配空白,即 空格,tab键
- 6.\S匹配非空白
- 7.\w匹配非特殊字符,即a-z、A-Z、0-9、_、汉字
- 8.\W匹配特殊字符,即非字母、非数字、非汉字
- 总结
正则表达式的介绍
1)在实际开发过程中经常会有查找符合某些复杂规则的字符串的需要,比如:邮箱、手机号码等,这时候想匹配或者查找符合某些规则的字符串就可以使用正则表达式了。
2)正则表达式就是记录文本规则的代码
re模块
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个 re 模块
# 导入re模块
import re
# 使用match方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据的话,可以使用group方法来提取数据
result.group()
# 导入re模块
import re
# 使用match方法进行匹配操作
result = re.match("test","test.cn")
# 获取匹配结果
info = result.group()
print(info)
结果:
test
re.match() 根据正则表达式从头开始匹配字符串数据如果第一个匹配不成功就会报错
匹配单个字符
1.匹配任意一个字符
# 匹配任意一个字符
import re
ret = re.match(".","x")
print(ret.group())
ret = re.match("t.o","too")
print(ret.group())
ret = re.match("o.e","one")
print(ret.group())
运行结果:
x
too
one
2.匹配[ ]中列举的字符
import re
ret = re.match("[hH]","hello Python")
print(ret.group())
ret = re.match("[hH]","Hello Python")
print(ret.group())
运行结果:
h
H
3.\d匹配数字,即0-9
import re
ret = re.match("神州\d号","神州6号")
print(ret.group())
运行结果:
神州6号
4.\D匹配非数字,即不是数字
non_obj = re.match("\D", "s")
print(non_obj .group())
运行结果:
s
5.\s匹配空白,即 空格,tab键
match_obj = re.match("hello\sworld", "hello world")
print(match_obj .group())
运行结果:
hello world
6.\S匹配非空白
match_obj = re.match("hello\Sworld", "hello&world")
result = match_obj.group()
print(result)
运行结果:
hello&world
7.\w匹配非特殊字符,即a-z、A-Z、0-9、_、汉字
match_obj = re.match("\w", "A")
result = match_obj.group()
print(result)
运行结果:
A
8.\W匹配特殊字符,即非字母、非数字、非汉字
match_obj = re.match("\W", "&")
result = match_obj.group()
print(result)
运行结果:
&
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注hwidc的更多内容!
【本文由:日本cn2服务器 提供 转载请保留URL】