
pytorch 搭建神经网路的实现
目录
- 1 数据
- (1)导入数据
- (2)数据集可视化
- (3)为自己制作的数据集创建类
- (4)数据集批处理
- (5)数据预处理
- 2 神经网络
- (1)定义神经网络类
- (3)模型参数
- 3 最优化模型参数
- (1)超参数
- (2)损失函数
- (3)优化方法
- 4 模型的训练与测试
- (1)训练循环与测试循环
- (2)禁用梯度跟踪
- 5 模型的保存、导入与GPU加速
- (1)模型的保存与导入
- (2)GPU加速
- 总结
1 数据
(1)导入数据
我们以Fashion-MNIST数据集为例,介绍一下关于pytorch的数据集导入。
PyTorch域库提供许多预加载的数据集(如FashionMNIST),这些数据集是torch.utils.data.Dataset的子类,并实现了特定于指定数据的功能。
Fashion-MNIST是Zalando文章中的图像数据集,包含60,000个训练示例和10,000个测试示例。每个示例包括28×28灰度图像和来自10个类中的一个的关联标签。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 没有这句会报错,具体原因我也不知道
training_data = datasets.FashionMNIST(
root="../data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="../data",
train=False,
download=True,
transform=ToTensor()
)
输出(下面的截图不完整)
我们使用以下参数加载FashionMNIST数据集:
root是存储训练/测试数据的路径,
train指定训练或测试数据集,
download=True 如果数据集不存在于指定存储路径,那么就从网上下载。
transform和target_transform用于指定属性和标签转换操作,这里所说的“转换操作”,通常封装在torchvision.transforms中,因此通常需要导入torchvision.transforms,或者导入这个包中的操作
(2)数据集可视化
我们可以像列表一样手动索引数据集:training_data[index]。我们使用matplotlib来可视化训练数据中的一些示例。
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
# 从0-len(training_data)中随机生成一个数字(不包括右边界)
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx] # 获得图片和标签
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off") # 坐标轴不可见
plt.imshow(img.squeeze(), cmap="gray") # 显示灰度图
plt.show()
输出

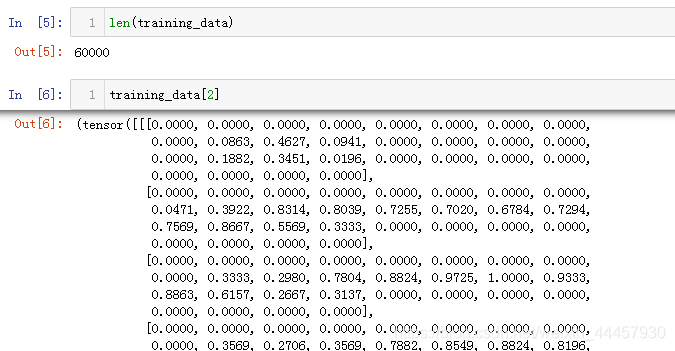
上面的程序中,有两个地方指的注意,一个是可以求training_data的长度,另一个可以通过索引获得单个样本,当然这里的样本已经被转换成了张量,如下图所示
(3)为自己制作的数据集创建类
如果要导入自己制作的数据集,需要编写一个类,这个类用于继承torch.utils.data中的Dataset类。自制的数据集类必须实现三个函数:init、len__和__getitem,分别是初始化类,求长度len(obj),通过索引获得单个样本(像列表一样)。
import os
import pandas as pd
from torch.utils.data import Dataset
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
具体细节可以在pytorch的官网教程:https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
Creating a Custom Dataset for your files
(4)数据集批处理
上面的程序中,虽然可以使用索引获得样本,但一次只能获得单个样本,无法像列表、张量、numpy切片一样一次切出多个
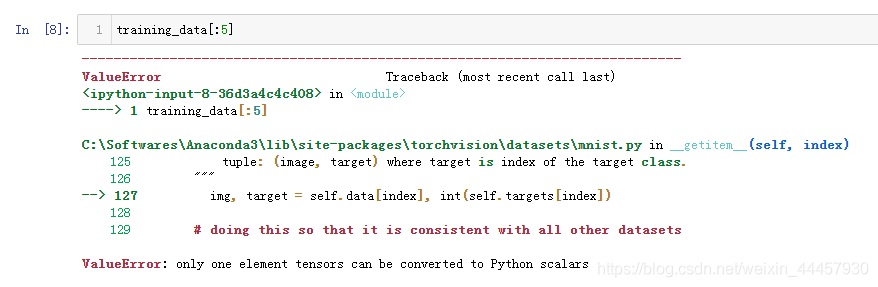
而在训练模型的时候,我们希望能够批处理,即一次处理若干个样本,同时,我们希望数据在每次遍历完之后打乱一次,以减少过拟合,并使用Python的多处理来加快数据提取。
pytorch中,专门有一个类可以实现上述功能,即torch.utils.data.DataLoader
下面的程序是将数据集导入到DataLoader中
from torch.utils.data import DataLoader train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # train_dataloader是一个DataLoader类的对象 test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
training_data和test_data就是前面导入的数据集,由于我们指定了batch的大小是64,因为我们指定了shuffle=True,所以在遍历所有batch之后,数据将被打乱。
此时training_data和test_data仍然不是可迭代对象,还需要将其变成可迭代对象,可以使用iter函数将每一个batch转化成可迭代对象,或者enumerate函数将其的每个batch带上序号变成元组
用iter函数
for batch_index, (features, label) in enumerate(train_dataloader):
print(batch_index)
print(f"Feature batch shape: {features.size()}")
print(f"Labels batch shape: {label.size()}")
img = features[0].squeeze()
label = label[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
break
输出

上面的程序中,train_features, train_labels都是包含64个样本的张量
用enumerate函数
for batch_index, (features, label) in enumerate(train_dataloader):
print(batch_index)
print(f"Feature batch shape: {features.size()}")
print(f"Labels batch shape: {label.size()}")
img = features[0].squeeze()
label = label[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
break

(5)数据预处理
数据并不总是以训练机器学习算法所需的最终处理形式出现,因此我们需要对数据进行一些变换操作,使其适合于训练。
所有的TorchVision数据集都有两个参数,它们接受包含转换逻辑的可调用对象:(1)transform用于修改特性,(2)target_transform用于修改标签
torchvision.transforms模块提供了多种常用的转换,这里我们介绍一下ToTensor和Lambda。
为了进行训练,我们需要将FashionMNIST中的特征转化为normalized tensors,将标签转化为One-hot编码的张量。为了完成这些变换,我们使用ToTensor和Lambda。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1))
)
ToTensor将PIL图像或NumPy ndarray转换为FloatTensor,并将图像的像素值(或者灰度值)缩放到[0, 1]区间
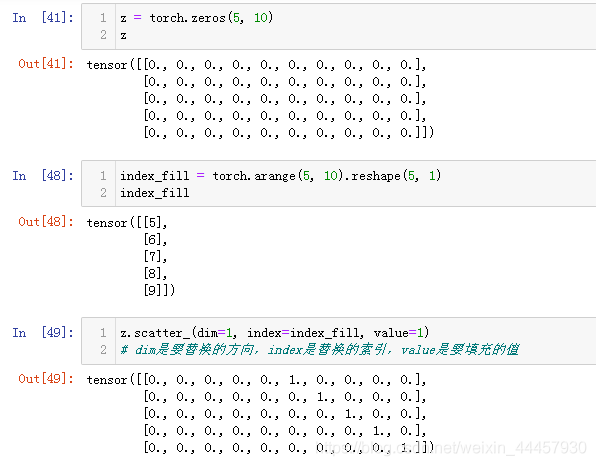
Lambda可以用于任何用户定义的lambda函数,在这里,我们定义一个函数来将整数转换为一个one-hot编码张量,首先建立一个长度为10的0张量(之所以为10,是因为有10个类别),然后调用scatter_函数,把对应的位置换成1。scatter_函数的用法如下:
更多torchvision.transforms的API详见:https://pytorch.org/vision/stable/transforms.html
2 神经网络
神经网络由对数据进行操作的层/模块组成,torch.nn提供了构建的神经网络所需的所有构建块。PyTorch中的每个模块都继承了nn.Module,神经网络本身就是一个模块,它由其他模块(层)组成,这种嵌套结构允许轻松构建和管理复杂的体系结构。
在下面的小节中,我们将构建一个神经网络来对FashionMNIST数据集中的图像进行分类。
(1)定义神经网络类
我们通过继承nn.Module来定义我们的神经网络类,并在__init__中初始化神经网络层,每一个nn.Module的子类在forward方法中继承了对输入数据的操作。
在初始化方法中搭建网络结构
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten() # 打平
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512), # 线性层
nn.ReLU(), # 激活层
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x) # 打平层
logits = self.linear_relu_stack(x) # 线性激活层
return logits
We create an instance of NeuralNetwork, and print its structure.
我们可以建立一个NeuralNetwork(即刚刚定义的类)的实例,并打印它的结构
model = NeuralNetwork() print(model)
输出
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
(5): ReLU()
)
)
使用模型时,我们将输入数据传递给它,这将执行模型的forward方法,以及一些背后的操作。注意:不要直接调用model.forward() !
定义好我们自己的神经网络类之后,我们可以随机生成一个张量,来测试一下输出的size是否符合要求
每个样本传入模型后会得到一个10维的张量,将这个张量传入nn.Softmax的实例中,可以得到每个类别的概率
X = torch.rand(1, 28, 28) # 生成一个样本
logits = model(X) # 将样本输入到模型中,自动调用forward方法
print(logits.size())
pred_probab = nn.Softmax(dim=1)(logits) # 实例化一个Softmax对象,并通过对象调用
y_pred = pred_probab.argmax(1) # 获得概率最大索引
print(f"Predicted class: {y_pred}")
输出
torch.Size([1, 10])
Predicted class: tensor([8])
(2)神经网络组件
上面搭建神经网络时,我们使用了打平函数、线性函数、激活函数,我们来看看这些函数的功能
打平层
input_image = torch.rand(3,28,28) print(input_image.size())
输出
torch.Size([3, 28, 28])
线性层
layer1 = nn.Linear(in_features=28*28, out_features=20) hidden1 = layer1(flat_image) print(hidden1.size())
输出
torch.Size([3, 20])
线性层其实就是实现了 y=w*x + b,其实是和下面的程序是等效的,但下面的程序不适合放在nn.Sequential中(但可以放在forward方法里)
w = torch.rand(784, 20) b = torch.rand((1, 20)) hidden2 = flat_image @ w + b print(hidden2.size())
输出
torch.Size([3, 20])
nn.Sequential是一个模块容器类,在初始化时,将各个模块按顺序放入容器中,调用模型时,数据按照初始化时的顺序传递。
例如:
seq_modules = nn.Sequential(
flatten, # 在nn.Sequential中可以调用其他模块
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)
在nn.Sequential中可以调用其他模块,nn.Sequential定义的模块也可以被其他模块调用
(3)模型参数
神经网络中的许多层都是参数化的,也就是说,在训练过程中会优化相关的权值和偏差,我们可以使用模型的parameters()或named_parameters()方法访问所有参数。
model.parameters()返回的是一个参数生成器,可以用list()将其转化为列表,例如
para_list = list(model.parameters())
# 将参数生成器转换成列表之后,列表的第一个元素是w,第二个元素是b
print(type(para_list[0]))
print(f'number of linear_layers :{len(para_list)/2}')
print('weights:')
print(para_list[0][:2]) # 只切出两个样本来显示
print('bias:')
print(para_list[1][:2])
print('\nthe shape of first linear layer:', para_list[0].shape)
输出
<class 'torch.nn.parameter.Parameter'>
number of linear_layers :3.0
weights:
tensor([[ 0.0135, 0.0206, 0.0051, ..., -0.0184, -0.0131, -0.0246],
[ 0.0127, 0.0337, 0.0177, ..., 0.0304, -0.0177, 0.0316]],
grad_fn=<SliceBackward>)
bias:
tensor([0.0333, 0.0108], grad_fn=<SliceBackward>)the shape of first linear layer: torch.Size([512, 784])
named_parameters()方法返回参数的名称和参数张量,例如:
print("Model structure: ", model, "\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : \n{param[:2]} \n")
# 只切出前两行显示
输出
Model structure: NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
(5): ReLU()
)
)
Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values :
tensor([[ 0.0135, 0.0206, 0.0051, ..., -0.0184, -0.0131, -0.0246],
[ 0.0127, 0.0337, 0.0177, ..., 0.0304, -0.0177, 0.0316]],
grad_fn=<SliceBackward>)Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values :
tensor([0.0333, 0.0108], grad_fn=<SliceBackward>)Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values :
tensor([[ 0.0338, 0.0266, -0.0030, ..., -0.0163, -0.0096, -0.0246],
[-0.0292, 0.0302, -0.0308, ..., 0.0279, -0.0291, -0.0105]],
grad_fn=<SliceBackward>)Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values :
tensor([ 0.0137, -0.0036], grad_fn=<SliceBackward>)Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values :
tensor([[ 0.0029, -0.0025, 0.0105, ..., -0.0054, 0.0090, 0.0288],
[-0.0391, -0.0088, 0.0405, ..., 0.0376, -0.0331, -0.0342]],
grad_fn=<SliceBackward>)Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values :
tensor([0.0406, 0.0369], grad_fn=<SliceBackward>)
更多关于torch.nn的API请看:https://pytorch.org/docs/stable/nn.html
3 最优化模型参数
(1)超参数
在绘制计算图之前,需要给出超参数,这里说的超参数,指的是学习率、批大小、迭代次数等
learning_rate = 1e-3 batch_size = 64 epochs = 5
(2)损失函数
回归问题一般用nn.MSELoss,二分类问题一般用nn.BCELoss,多分类问题一般用nn.CrossEntropyLoss,这里FashionMNIST中,标签有十个类别,因此这里我们用nn.CrossEntropyLoss
# Initialize the loss function loss_fn = nn.CrossEntropyLoss()
(3)优化方法
这里我们用随机梯度下降,即每传入一个样本,更新一次参数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
更多优化方法的API,可以看:https://pytorch.org/docs/stable/optim.html
常用的优化算法原理,可以看:https://zhuanlan.zhihu.com/p/78622301
4 模型的训练与测试
(1)训练循环与测试循环
每个epoch包括两个主要部分:
训练循环(train_loop)——遍历训练数据集并尝试收敛到最优参数。
验证/测试循环(test_loop)——遍历测试数据集以检查模型性能是否正在改善。
我们先把上述两个过程封装成函数
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss,下面两步相当于绘制计算图
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad() # 梯度信息清零
loss.backward() # 反向传播
optimizer.step() # 一旦有了梯度,就可以更新参数
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad(): # 禁用梯度跟踪,后面会讲
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
现在可以进行训练了
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
输出

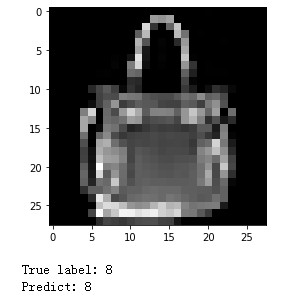
我们可以写一段代码,看看预测的图片对不对
test_features, test_labels = next(iter(test_dataloader))
logits = model(test_features[0])
pred_probab = nn.Softmax(dim=1)(logits)
pred = pred_probab.argmax(1)
img = test_features[0].squeeze() # 将长度为1的维度去掉
true_label = test_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"True label: {true_label}")
print(f"Predict: {pred.item()}")
输出
(2)禁用梯度跟踪
在上面的测试循环中,使用了torch.no_grad()方法,在表示所在的with块不对梯度进行记录。
默认情况下,所有requires_grad=True的张量(在创建优化器的时候,内部就把里面的参数全部设置为了requires_grad=True)都跟踪它们的计算历史并支持梯度计算。但是,在某些情况下,我们并不需要这样做,例如,测试的时候,我们只是想通过网络进行正向计算。我们可以通过使用torch.no_grad()块包围计算代码来停止跟踪计算:
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
输出
True
False
禁用梯度跟踪主要用于下面两种情况:
(1)将神经网络中的一些参数标记为冻结参数,这是对预先训练过的网络进行微调的一个常见的场景
(2)当你只做正向传递时,为了加快计算速度,因为不跟踪梯度的张量的计算会更有效率。
5 模型的保存、导入与GPU加速
(1)模型的保存与导入
PyTorch模型将学习到的参数存储在一个内部状态字典中,称为state_dict,我们可以通过torch.save()将模型的参数保存到指定路径。
保存了模型的参数,还需要保存模型的形状(即模型的结构)
# 保存模型参数 torch.save(model.state_dict(), './model_weights.pth') # 保存模型结构 torch.save(model, './model.pth')
导入模型时,需要先导入模型的结构,再导入模型的参数,代码如下:
# 导入模型结构
model_loaded = torch.load('./model.pth')
# 如果原来的model在cuda:0上,那么导入之后,model_loaded也在cuda:0上
# 导入模型参数
model_loaded.load_state_dict(torch.load('model_weights.pth'))
因为model是NeuralNetwork类的一个对象,所以在导入状态前,必须先有一个NeuralNetwork对象,要么实例化一个,要么通过导入结构torch.load('./model.pth')导入一个.
torch.load直接导入模型,不是特别推荐,原因有以下两点:
(1)如果A.py文件中的程序保存了model.pth,如果文件B.py想读取这个模型,则不能直接用torch.load导入模型结构,必须先实例化一个NeuralNetwork对象,要么从A.py或者从其他文件中把NeuralNetwork类给导进来,要么这里重写一个与A.py中一模一样的NeuralNetwork类,类名也要一样,否则报错。
# 实例化一个NeuralNetwork对象
model_loaded = NeuralNetwork() # model_loaded默认是CPU中
# 导入模型参数
model_loaded.load_state_dict(torch.load('./gdrive/MyDrive/model_weights.pth'))
(2)如果用torch.load导入模型,当我们在cuda:0上训练好一个模型并保存时,读取出来的模型也是默认在cuda:0上的,如果训练过程的其他数据被放到了如cuda:1上,则会报错。而实例化创建模型,由于.load_state_dict可以跨设备,则无论原来的模型在什么设备上,都不妨碍把参数导入到新创建的模型对象当中。
综合上面两点,torch.load慎用,最好是先实例化后再导入模型状态。
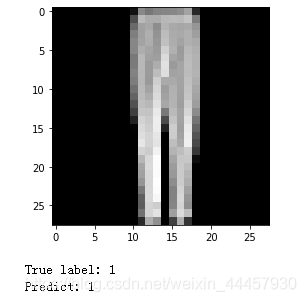
我们可以用导入的模型做预测
test_features, test_labels = next(iter(test_dataloader))
logits = model_loaded(test_features[0]) # 使用导入的模型
pred_probab = nn.Softmax(dim=1)(logits)
pred = pred_probab.argmax(1)
img = test_features[0].squeeze() # 将长度为1的维度去掉
true_label = test_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"True label: {true_label}")
print(f"Predict: {pred.item()}")
输出
(2)GPU加速
默认情况下,张量和模型是在CPU上创建的。如果想让其在GPU中操作,我们必须使用.to方法(确定GPU可用后)显式地移动到GPU。需要注意的是,跨设备复制大张量在时间和内存上开销都是很大的!
# We can move our tensor to the GPU if available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
输出
Using cuda device
在初始化模型时,可以将模型放入GPU中
model = NeuralNetwork().to(device)
对于张量,可以在创建的时候指定为在GPU上创建,也可以在创建后转移到GPU当中
X = torch.rand(1, 28, 28, device=device) # 创建时指定设备 Y = torch.rand(10).to(device) # 创建后转移
当然,张量和模型也能从GPU转移到CPU当中,我们可以用.device()来查看张量所在设备

另外,需要注意的是,如果需要将模型送到GPU当中,必须在构建优化器之前。因为CPU和GPU中的模型,是两个不同的对象,构建完优化器再将模型放入GPU,将导致优化器只优化CPU中的模型参数。
有些电脑有多张显卡,那么.to(‘cuda')默认是将张量或者模型转移到第一张显卡(编号为0)上,如果想转移到其他显卡上,则用下面的程序
device = torch.device(‘cuda:2') # 2是设备号,假如有八张显卡,那么编号就是0—7
torch.save
至此,所有程序已经完成
总结
上面的程序有点乱,我这里综合一下:
# coding=utf-8
import torch
import torch.nn as nn
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 没有这句会报错,具体原因我也不知道
# 导入数据
training_data = datasets.FashionMNIST(
root="../data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="../data",
train=False,
download=True,
transform=ToTensor()
)
# 定义超参数
# 之所以在这个地方定义,是因为在初始化DataLoader时需要用到batch_size
learning_rate = 1e-3
batch_size = 64
epochs = 5
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True)
# train_dataloader是一个DataLoader类的对象
test_dataloader = DataLoader(test_data, batch_size=batch_size, shuffle=True)
# 搭建神经网络
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten() # 打平
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512), # 线性层
nn.ReLU(), # 激活层
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x) # 打平层
logits = self.linear_relu_stack(x) # 线性激活层
return logits
# 确定使用设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 实例化一个神经网络类
model = NeuralNetwork().to(device)
# 确定损失函数
loss_fn = nn.CrossEntropyLoss()
# 确定优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 封装训练过程
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) # 将样本和标签转移到device中
# Compute prediction and loss,下面两步相当于绘制计算图
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad() # 梯度信息清零
loss.backward() # 反向传播
optimizer.step() # 一旦有了梯度,就可以更新参数
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# 封装测试过程
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 将样本和标签转移到device中
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# 训练
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
# 保存模型参数
torch.save(model.state_dict(), './model_weights.pth')
# 保存模型结构
torch.save(model, './model.pth')
# 导入模型结构
model_loaded = torch.load('./model.pth') # 模型自动导入到GPU当中
# 导入模型参数
model_loaded.load_state_dict(torch.load('model_weights.pth'))
# 用导入的模型测试
test_features, test_labels = next(iter(test_dataloader))
test_features = test_features.to(device)
logits = model_loaded(test_features[0]) # 使用导入的模型
pred_probab = nn.Softmax(dim=1)(logits)
pred = pred_probab.argmax(1)
# 可视化
img = test_features[0].squeeze() # 将长度为1的维度去掉
img = img.to('cpu') # 绘图时,需要将张量转回到CPU当中
true_label = test_labels[0] # 标签是否转移到CPU无所谓,因为没有用于plt的方法中
plt.imshow(img, cmap="gray")
plt.show()
print(f"True label: {true_label}")
print(f"Predict: {pred.item()}")
到此这篇关于pytorch 搭建神经网路的实现的文章就介绍到这了,更多相关pytorch 神经网路内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【来源:美国站群服务器 请说明出处】