
python使用pandas按照行数分割表格
目录
- 问题
- 思路
- 代码实现
- 测试效果
问题
- 一张excel表格,大概1万行,需要录入系统
- 系统每次最多只能录入500行表格数据,一旦超过500行,就会录入失败
- 需要把1万行的数据按照500行分割,形成20个表格,这样才能录入系统
思路
- 使用pandas得到总行数,比如10002行,分割表格的时候,要保留一行表头
- 第一张表,是1-500行,第二张表是 501-1000,以此类推
- 最后一张表应该是1000-10002行,生成的表格数量是10000/500+1,21张
- 生成的表格按照顺序保存到一个目录中
- 写一个函数,可以按照任意指定的分割数量进行分割。
代码实现
#按行数分割表格函数
#问题
#1.如果有有一个十万行表格,要录入系统,但是系统每次最多只能录入500行?
#解决问题:
#1.按照指定的行数分割表格
#2.分割出来的表格按照序号命名
import pandas as pd
import os
def SplitExcel(file,num):
file_dir='result' #创建目录
if os.path.isdir(file_dir):
os.rmdir(file_dir)
else:
os.mkdir(file_dir)
n = 1
row_list = []
df = pd.DataFrame(pd.read_excel(file, sheet_name=0))
row_num = int(df.shape[0]) # 获取行数
if num >= row_num: #如果分割行数大于总行数,报错
raise Exception('too much!!')
try:
for i in list(range(num,row_num,num)):
row_list.append(i)
row_list.append(row_num) # 得到完整列表
except Exception as e:
print (e)
(name,ext)=os.path.splitext(file) #获取文件名
for m in row_list:
filename=os.path.join(file_dir,name+'-' + str(n) + '.xlsx')
if m <row_num:
df_handle=df.iloc[m-num:m] #获取n行之前
print (df_handle)
df_handle.to_excel(filename , sheet_name='sheet1',index=False)
elif m == int(row_num):
remainder=int(int(row_num)%num) #余数
df_handle=df.iloc[m-remainder:m] #获取最后不能整除的行
df_handle.to_excel(filename , sheet_name='sheet1', index=False)
n = n + 1
if __name__=='__main__':
file= 'result.xls'
SplitExcel(file,num=10)
测试效果
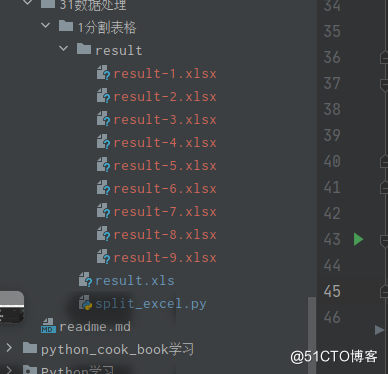
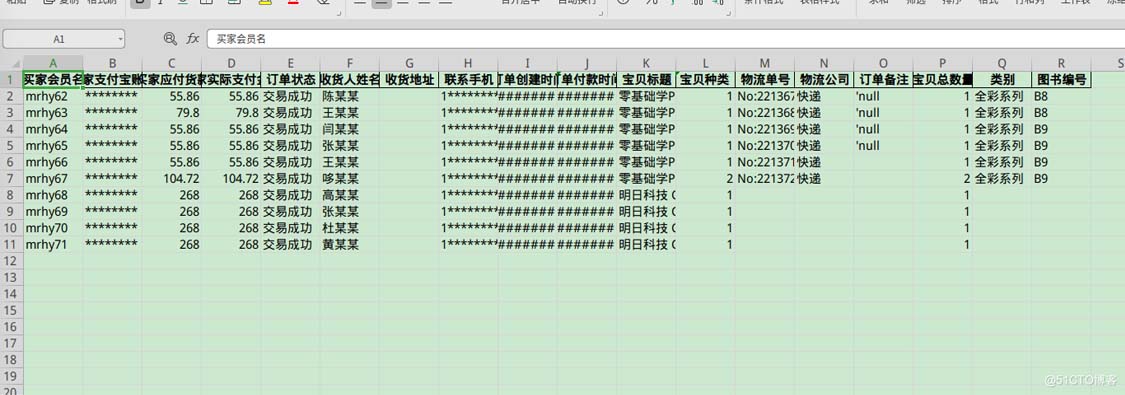
一张83行的表格,去除表头,一共82行,按照10行分割,一共要获得9张表格,最后一张表格,应该只有两行,中间的表格,数据必须是连续的,
分割前
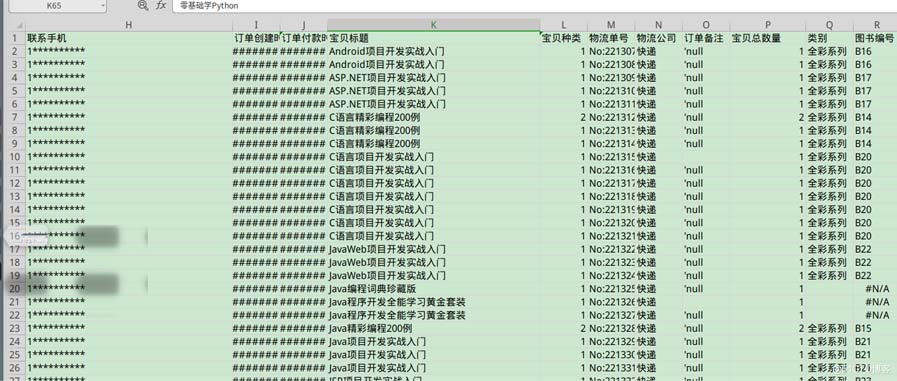
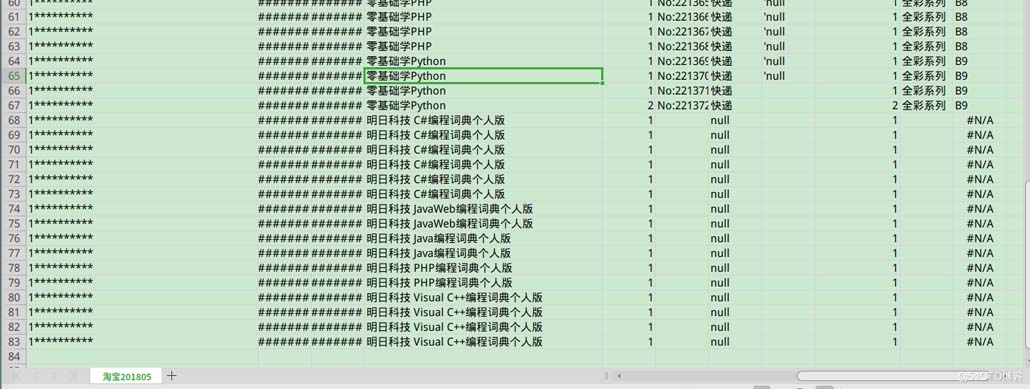
分割后

到此这篇关于python使用pandas按照行数分割表格的文章就介绍到这了,更多相关pandas按行分割表格内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章转自:韩国cn2服务器 转载请保留连接】