
python利用numpy存取文件案例教程
NumPy提供了多种存取数组内容的文件操作函数。保存数组数据的文件可以是二进制格式或者文本格式。二进制格式的文件又分为NumPy专用的格式化二进制类型和无格式类型。
numpy格式的文件可以保存为后缀为(.npy/.npz)格式的文件
1. tofile()和fromfile()
- tofile()将数组中的数据以二进制格式写进文件
- tofile()输出的数据不保存数组形状和元素类型等信息
- fromfile()函数读回数据时需要用户指定元素类型,并对数组的形状进行适当的修改
import numpy as np
# 随机生成12个数字并将其有一维转换成3*4的矩阵形式
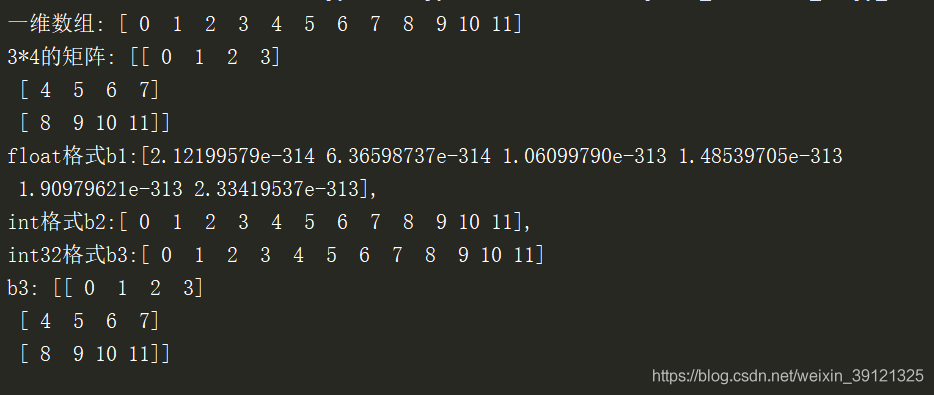
a = np.arange(12)
print("一维数组:",a)
a.shape = 3,4
print("3*4的矩阵:",a)
# 将数组中的数据以二进制格式写入到文件
a.tofile('a.bin')
# fromfile在读取numpy文件时需要自己指定数据格式,并且原格式并为保存
b1 = np.fromfile('a.bin', dtype=np.float) # 按照float读取数据
b2 = np.fromfile('a.bin', dtype=np.int) # 按照int读取数据
b3 = np.fromfile('a.bin', dtype=np.int32) # 按照int32读取数据
print('float格式b1:{},\nint格式b2:{},\nint32格式b3:{}'.format(b1,b2,b3))
b3.shape = 3,4
print('b3:',b3)
2. save() 和 load(),savez()
- NumPy专用的二进制格式保存数据,它们会自动处理元素类型和形状等信息
- 如果想将多个数组保存到一个文件中,可以使用savez()
- savez()的第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数为数组起名
- 非关键字参数传递的数组会自动起名为arr_0、arr_1、...。
- savez()输出的是一个扩展名为npz的压缩文件,其中每个文件都是一个save()保存的npy文件,文件名和数组名相同
- load()自动识别npz文件,并且返回一个类似于字典的对象,可以通过数组名作为键获取数组的内容
import numpy as np
a = np.arange(12)
a.shape = 3,4
# 将数据存储为npy/npz
np.save('a.npy', a)
np.save('a.npz', a)
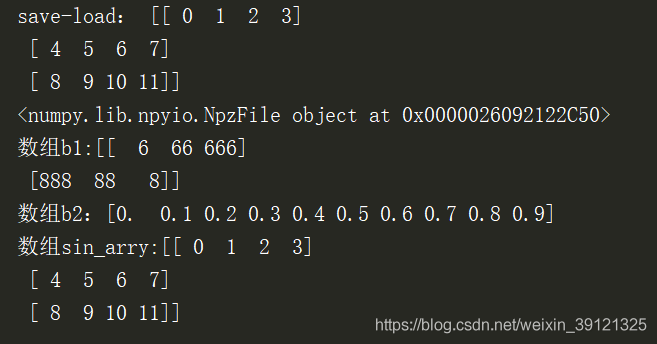
c = np.load('a.npy')
print('save-load:',c)
# 存储多个数组
b1 = np.array([[6, 66, 666],[888, 88,8]])
b2 = np.arange(0, 1.0, 0.1)
c2 = np.sin(b2)
np.savez('result.npz', b1,b2,sin_arry = c)
c3 = np.load('result.npz') # npz文件时一个压缩文件
print(c3)
print("数组b1:{}\n数组b2:{}\n数组sin_arry:{}".format(c3['arr_0'],c3['arr_1'],c3['sin_arry']))
3. savetxt() 和 loadtxt()
- 读写1维和2维数组的文本文件
- 可以用它们读写CSV格式的文本文件
用这种方式来对数据进行存储,方便深度学习中, 保存了训练集,验证集,测试集,还包括他们的标签,用这个方式存储起来,要啥加载啥,文件数量大大减少,也不会到处改文件名。算是get到了另外一种好的存储数据的方式
参考:https://www.cnblogs.com/wushaogui/p/9142019.html
https://www.cnblogs.com/dmir/p/5009075.html
到此这篇关于python利用numpy存取文件案例教程的文章就介绍到这了,更多相关python利用numpy内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【转自:http://www.1234xp.com/xggf.html 欢迎转载】