
Java 使用maven实现Jsoup简单爬虫案例详解
一、Jsoup的简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据
二、我们可以利用Jsoup做什么
2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据,
2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本
2.3从而使我们输出我们想要的整洁文本
三、利用Jsoup爬取某东示例
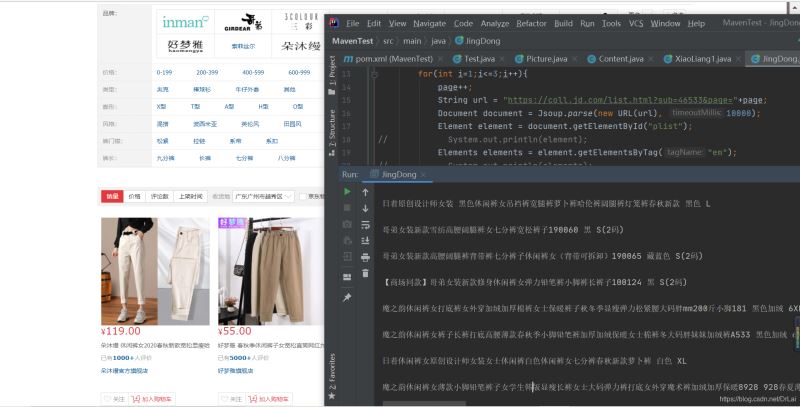
可以从图中看到,成功爬取某东的女装热门销量从高到低的标题,从而可以分析到销量高(或者是综合排序)在前列的标题名称。从而可以剖析出热门商品的命名规范。
四、Jsoup用法
4.1先创建maven工程,在maven工程上注入依赖
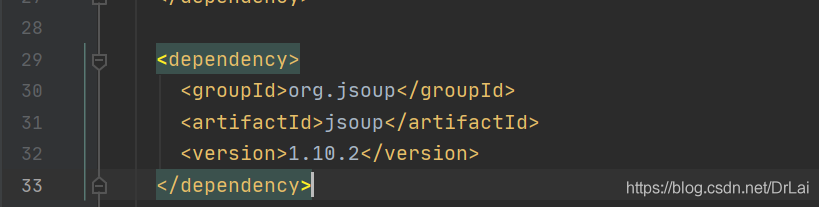
4.2 注入依赖后需要导入依赖,否则在程序中使用Jsoup会全部报错。
4.3利用JSP的知识找出目标元素
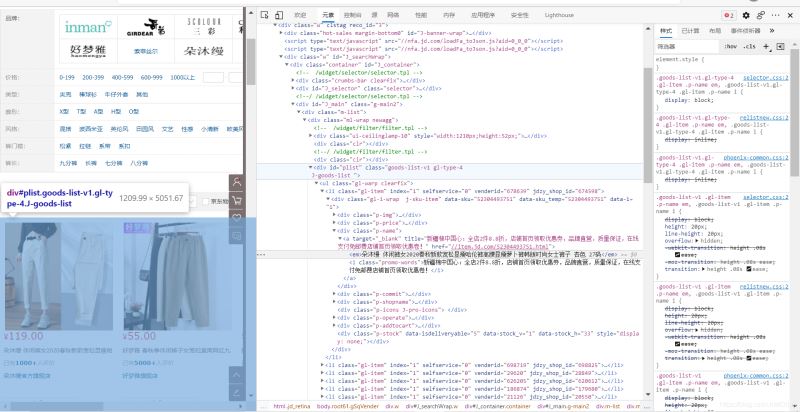
如在某东界面我们发现, 控制目标页面的ID为"plist",则我们使用
getElementById("plist");方法去获取到他的ID
接着获取目标标题,可以由上图分析得,标题是由<em>标签所控制,因此我们需要用到
getElementsByTag("em");去捕捉到em的部分
最后循环输出他的部分即可。

五、总结
Jsoup只能应用于简单的页面捕捉,在实际开发中许多网站采用Ajax技术等使得模块在动态变化抑或是有反爬虫技术,因此本技术有局限性。熟悉前端jsp技术的同学应该会游刃有余。
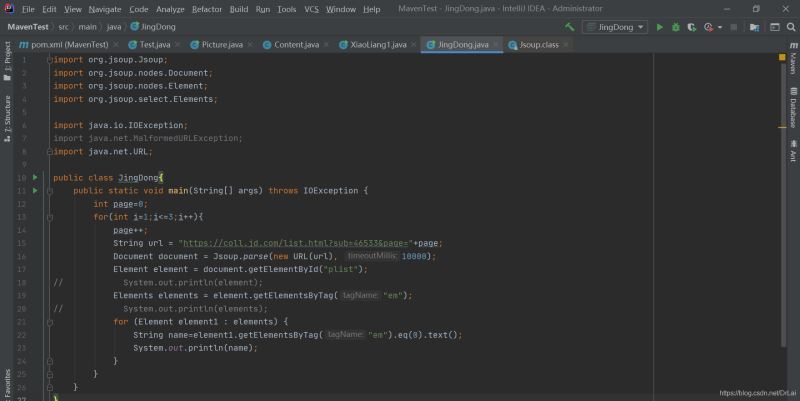
最后附上所有代码
到此这篇关于Java 使用maven实现Jsoup简单爬虫案例详解的文章就介绍到这了,更多相关Java 使用maven实现Jsoup简单爬虫内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!
【本文由:http://www.nextecloud.cn/flb.html提供,感谢】