
一文聊聊如何高效开发表现层Node.js应用
如何使用 Node.js 进行前端应用的开发?下面本篇文章给大家介绍一下高效开发表现层 Node.js 应用的方法,涉及到表现层应用的开发。我今天分享的方案是针对简单场景的,旨在让前端开发人员不必掌握太多关于 Node.js 的背景知识和专业知识,即使没有代码编写经验,也能完成一些简单的服务端开发任务。

我很多小公司都面临着这样的情况:大公司的开发人员更喜欢专注于专业,需要掌握 ORM、服务器和运维等专业知识,但在小公司,我们可以直接上手完成开发任务。因此,我的方案是介绍一系列工具的组合,这些工具是我在创业公司里的一些尝试,我想简单地和大家分享一下。
这里展示的内容实际上就是我今天想讲的全部内容。【相关教程推荐:nodejs视频教程、编程教学】

底层是 Nest.js 开发框架,实际上,使用什么框架不是很重要,因为它只提供最基本的功能,这些功能是所有框架都具有的。Nest.js 封装了网络层和应用分层,在国外使用较多,因为它的开发方式与 Spring Boot 类似,所以对于熟悉 Java 的人来说很熟悉。
上层使用的是名为 Prisma 的 ORM,它是一个比较特殊的 ORM,是一个比较纯粹的 ORM,是 Model 层的 ORM。我今天的整个方案是通过 Prisma 将所有开发流程串联起来,将多个工具连接在一起。基本上,你只需要写很少的代码,就可以完成从底层数据层到顶层控制层再到整个 API 文档的应用开发方案。
我最近比较关注的是这种渐进增强的方案,很多国外社区的方案都注重这一点。也就是说,这些方案都是可插拔的,包括我今天讲的内容,你可以选择使用或者不使用,或者只使用其中的一部分,而不会影响其他开发工作。所以,如果你的公司还比较小,而且想让前端负责这部分工作,你可以让他们简单地使用这些工具。但是当你的公司或者团队发展之后,你可能需要专业的 Node.js 开发人员,他们了解 ORM、数据库、缓存等知识。这时你可以卸载上层的工具,使用 Nest.js,甚至将 Nest.js 替换成其他框架。这是一种灵活的思路,上层工具的耦合度很低,是可替换的。
这就是我今天要介绍的三个核心工具, Nest.js,Prisma,GraphQL。这三者都非常重要。

Prisma
首先简单介绍一下 Prisma,Prisma 在官网上的介绍是它是「Next-generation Node.js and TypeScript ORM」,强调了它对类型的强大支持。
关于 Prisma 的使用,实际上它是一个 ORM 工具,但它的重点并不是让你自己去定义模型、类等等,而是在进入使用时首先要定义一个描述文件。这个描述文件与熟悉 GraphQL 的同学应该都知道,GraphQL 有两种开发方式,一种是架构优先,一种是代码优先。而 Prisma 作为一个整套方案,在国外与 GraphQL 有着紧密的联系,但它们之间的耦合并不是特别严格,而是比较轻松的。
因此,在 Prisma 的开发中,首先要定义一个描述文件,其中包括
- 定义 Model(数据模型),这是每个 ORM 都需要做的事情。
- 定义 DataSource(数据源),这是因为在 Prisma 中,它接管了与数据库的连接,这一层被包含在整个库中,所以你不需要关注如何连接数据库,而是由 Prisma 内部进行数据库连接的管理。
- 定义 Generator(生成器),是 Prisma 的核心重点。它定义了数据模型和数据连接管理方式。Generator 其实是在定义一些官方和第三方的生成工具,它可以生成强类型的 GraphQL schema 的 JS 包,生成类型的 DTO 的定义,还有 GraphQL Schema 的定义。


所以在使用 Prisma 时,你可能会发现它的用法有些奇怪。通常情况下,当你使用其他库时,你只需要直接引用 Node models 中的 ORM 的代码。但是,Prisma 中 Node models 的代码是在运行时动态生成的,它并不是在你下载下来的时候就已经存在的。所以,在使用 Prisma 时,实际上你并没有去定义像我刚才在右边代码中写的「this.prisma.tag」这样的模型,但是你却可以将它当作一个正常的对象来使用。
当然,Prisma 还有很多其他的特性,我刚才只列举了一部分。
Prisma 提供了一套数据订正的工具。实际上很多 ORM 都已经在使用这种特性了。但是在一些小型公司或者小型产品中,使用这个工具其实非常方便。然而,在一些大型团队中,使用这种数据订正工具可能会比较困难。不过,在这方面,Prisma 在这块的功能实际上做得比较成熟。
当你需要修改一个 Model 中的任何信息时,它都会帮你生成订正的语句,而且会进行预测,例如,如果你之前删除了一个字段,而这个字段里面有信息,并且是必填的,而你现在把它改成了非必填,那么这时候系统会生成一条非常复杂的订正语句,它会进行预测并让你做出选择。
因此,在某些小型场景中,这个数据订正工具非常方便。最后,它会生成一个订正的记录,并可以将这个订正记录同步到你的 Git 中。关于在生产环境中是否需要使用这套工具,这里我就不详细展开了。
无码有码,全靠拖拉。跟早早聊一起,玩转低代码,上车链接:www.zaozao.run/conf/c63
Nest.js
接下来是关于 Nest.js 框架的简单介绍。这个框架实际上与许多其他框架非常类似,它实现了一些分层和全局钩子等机制,用于串联各种开发工具。我想要在 Nest.js 中尽量减少编写逻辑的数量。
因此,大家最终可以看到,在 Nest.js 端实现了一个完整的增删改查操作,甚至包括复杂的操作,基本上没有代码。因此,我只会简单地介绍一下这个框架是什么样的。
Nest.js 框架实际上有三个核心概念:Controller,Provider,Moduler。
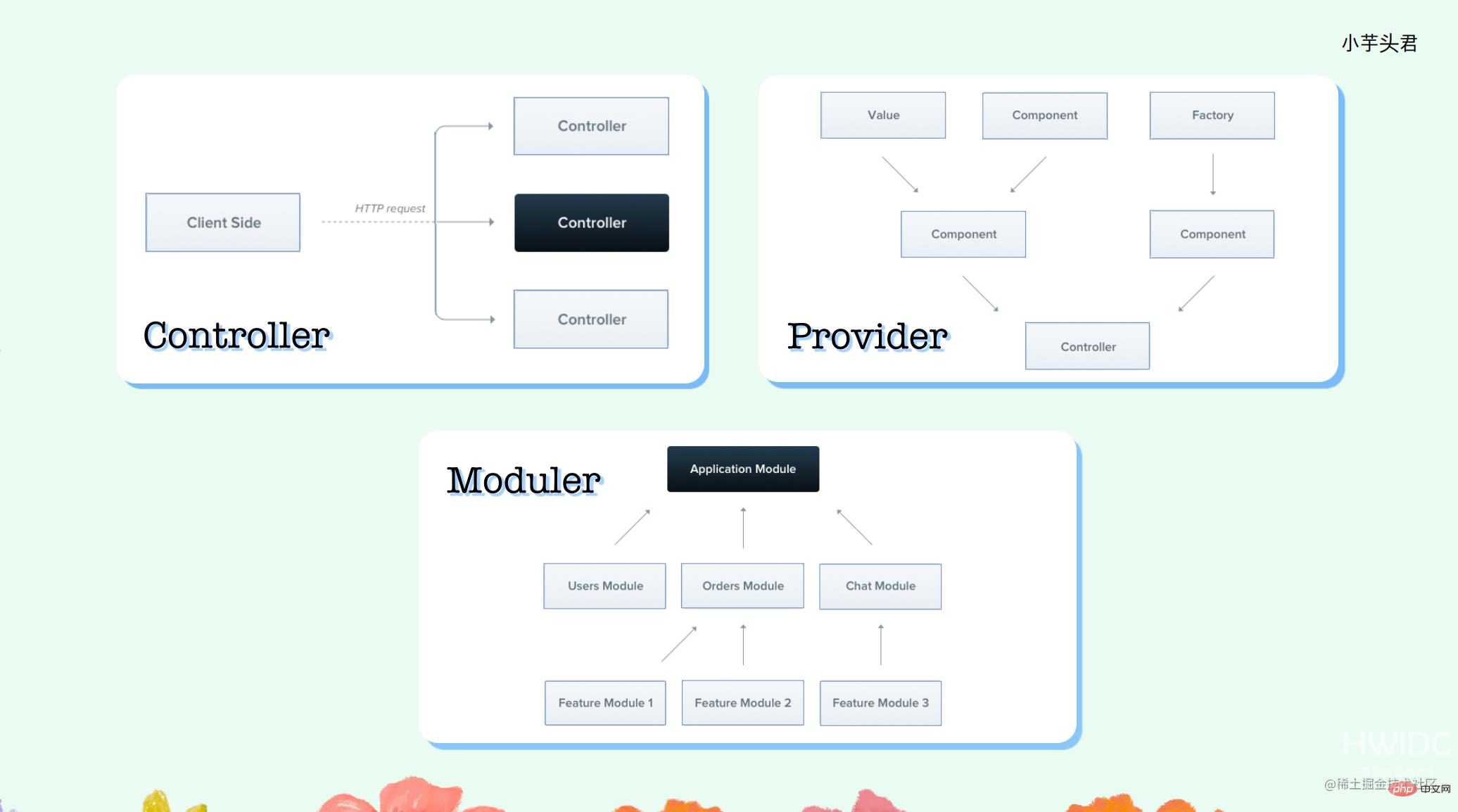
最底层、最重要的是 Moduler,它是用来组织一个完整业务逻辑中的所有模块的总入口。每个 Moduler 都有一个完整的分层,入口是 Controller,所有的请求都首先进入 Controller 层。Provider 即服务层,主要提供一些类似于平常编写的 service 层逻辑的功能。
大家可以看到,这里没有明确的提到 Model 层。虽然在模型层中有一些定义,但今天我们使用的是 Prisma,它基本上占用了 Model 层。因此,开发一个 Nest.js 的流程实际上是一个正常的开发流程,即当应用进来时,需要写 controller,service,定义 DTO 和 VO。
一旦有了 Prisma 之后,我们可以使用 Prisma 生成一个 ORM 的库 ,同时它还会帮助我们生成一些 DTO 和 VO 的代码,所以我们只要关注 controller 和 service。此外,Nest.js 还提供了一个用于增加、删除、修改、查询的一个脚手架。当执行了这个命令后,它会为你生成一个类似于下面这个图中的文件结构,然后你只需要填充其中的 controller 和 service 即可。

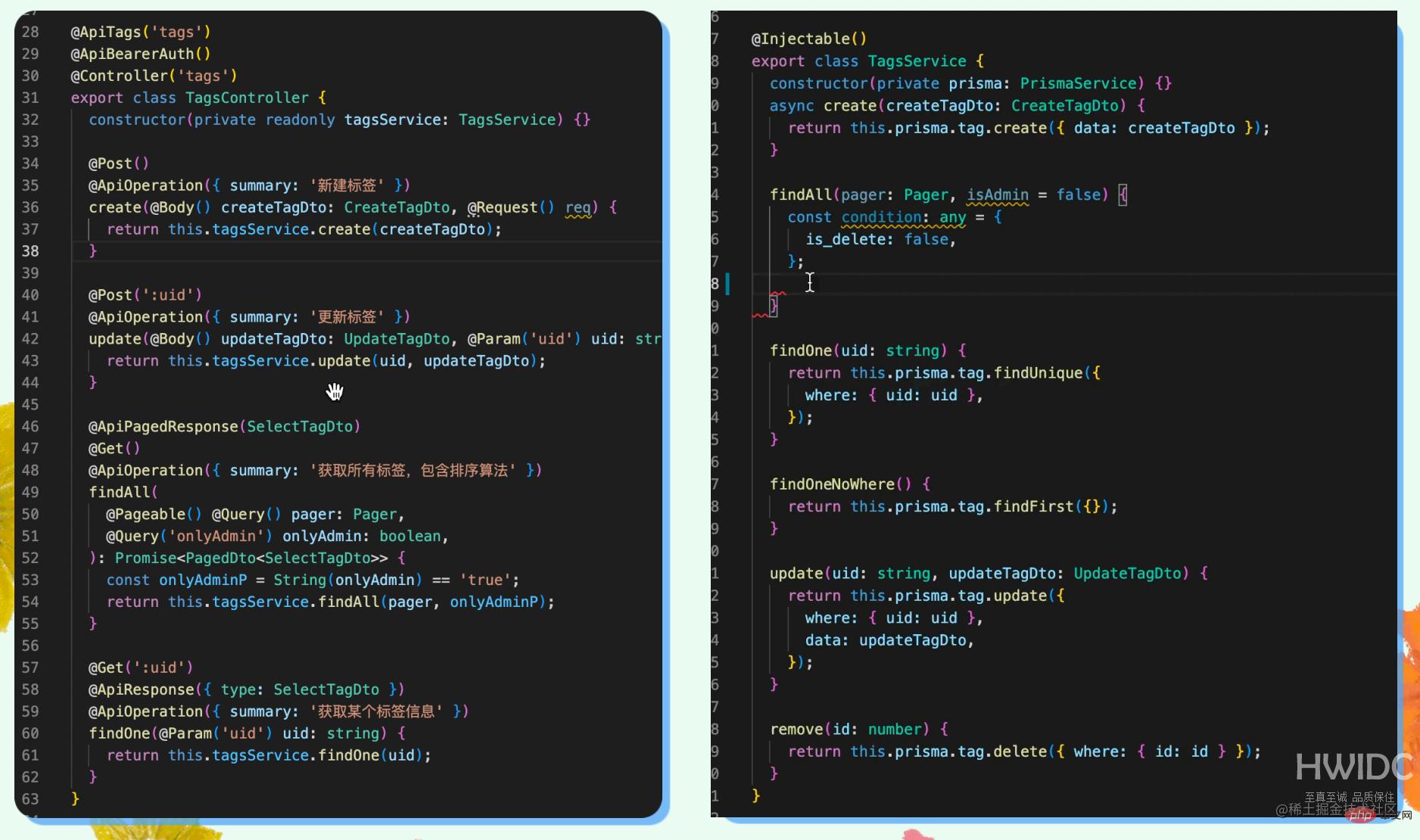
大家看似简单,就是生成了一个 Controller,然后手写了一些代码,就是那个 CRUD 工具,但其实这些是非常初级的,不能帮你生成逻辑代码。所以要自己去定义参数的类型,调用 Service 层。当然,这个 Controller 层的代码还是比较简单的,不需要做太多事情,逻辑都在 Service 层。在这里需要写增删改查的逻辑,例如基本的分页和条件过滤等技术,以及联合查询等。
我不希望前端变成一个服务端的开发者。前端写服务端的意义是什么呢?尤其对于一个小团队来说,为什么要这么做呢?其实我觉得这个框架的初衷并不是让前端变成一个服务端的开发者,而且这样做可能会遭到后端开发者的质疑,我用 Spring Boot 写得很好,为什么要用 Nest.js?它有什么本质上的改变吗?其实并没有。
所以为什么要让前端尝试去做一些服务端的开发呢?其实我初衷是为了提高效率,面对一个小的普通界面上的更改,避免前端设计师、前端开发人员和服务端开发人员都要参与才能完成此次更改,从而减少效率损耗。我希望前端尽量少碰服务端的代码,但同时又能灵活地调整接口,以适应前端的不断变更。所以我不希望大家去写类似于 find、where、select、count 等这样的代码,因为对于不太熟悉这些概念的前端来说,很容易写出问题来,而且我也不希望花太多精力去监督他们如何写这些东西。
接下来我会继续详细介绍。这里,大家可以看到 Prisma 类型是非常强的,不仅仅是模型的类型,还包括模型生成的操作类的类型,以及各种查询条件的类型,非常精细。实际上,所有使用的东西的类型都是强类型,都是根据模型定义推导出来的。因此,在它的定义中,它标明了它是一个 TypeScript 的 ORM,这是它的优势之一。
如果你要使用 Nest.js,不管你使用什么框架,你都要做一些其他的事情,比如身份验证、异常处理、请求返回的统一封装和配置等。
网上有一些资料,但有时候描述得不是很完整。因此,我做了一个示例,如果大家需要使用的话,可以从我的 GitHub 项目中 clone 出来,这样可以避免很多坑。
我们刚刚完成了一个正常的 Nest.js 和 Prisma 的应用程序开发,实际上代码量不多,对于我这种之前做过 Node.js 服务端开发的人来说没有太大的压力。但是对于一个前端开发者来说,我向他介绍这些东西,他可能会有些难以接受,那是否可以在不编写代码的情况下完成复杂的查询、插入、更新和删除逻辑,并且能够灵活调整前端界面?
欢迎报名第 63 届早早聊大会 - 低代码无代码,了解如何通过低代码平台提高生产力,玩转低代码。上车戳:www.zaozao.run/conf/c63
GraphQL
要解决上面的问题,我们可以引入 GraphQL,这实际上是一种面向前端的接口开放方式。GraphQL 并不是一个万能药,不是说通过 GraphQL 提供的接口就变得高级了,或者解决了很多问题。实际上,它只适用于某些场景,特别是它最初设计的树状数据结构,而不是图状数据结构,可能在树状数据结构的场景下更加适合。
但是今天我的话题核心实际上是 Prisma 和 GraphQL 的配合。虽然 Prisma 的官方定义中没有提到这一点,但是如果你查看官方文档,它有一个关于 Prisma 和 GraphQL 如何一起使用的话题。
在这里我使用了两个工具。
prisma-nestjs-graphql
第一个工具是我要用 Prisma 的 Schema 生成 GraphQL 的 Schema,这个工具实在不断演进。我使用的是它之前的一个版本,prisma-nestjs-graphql,这个库的名字非常直白,就是将这三者连接起来,通过执行 Prisma 的 generate 命令,可以在项目中生成内容。生成的内容不仅包括 Model 的定义(例如 tags),还会生成一些定义这些操作的参数。
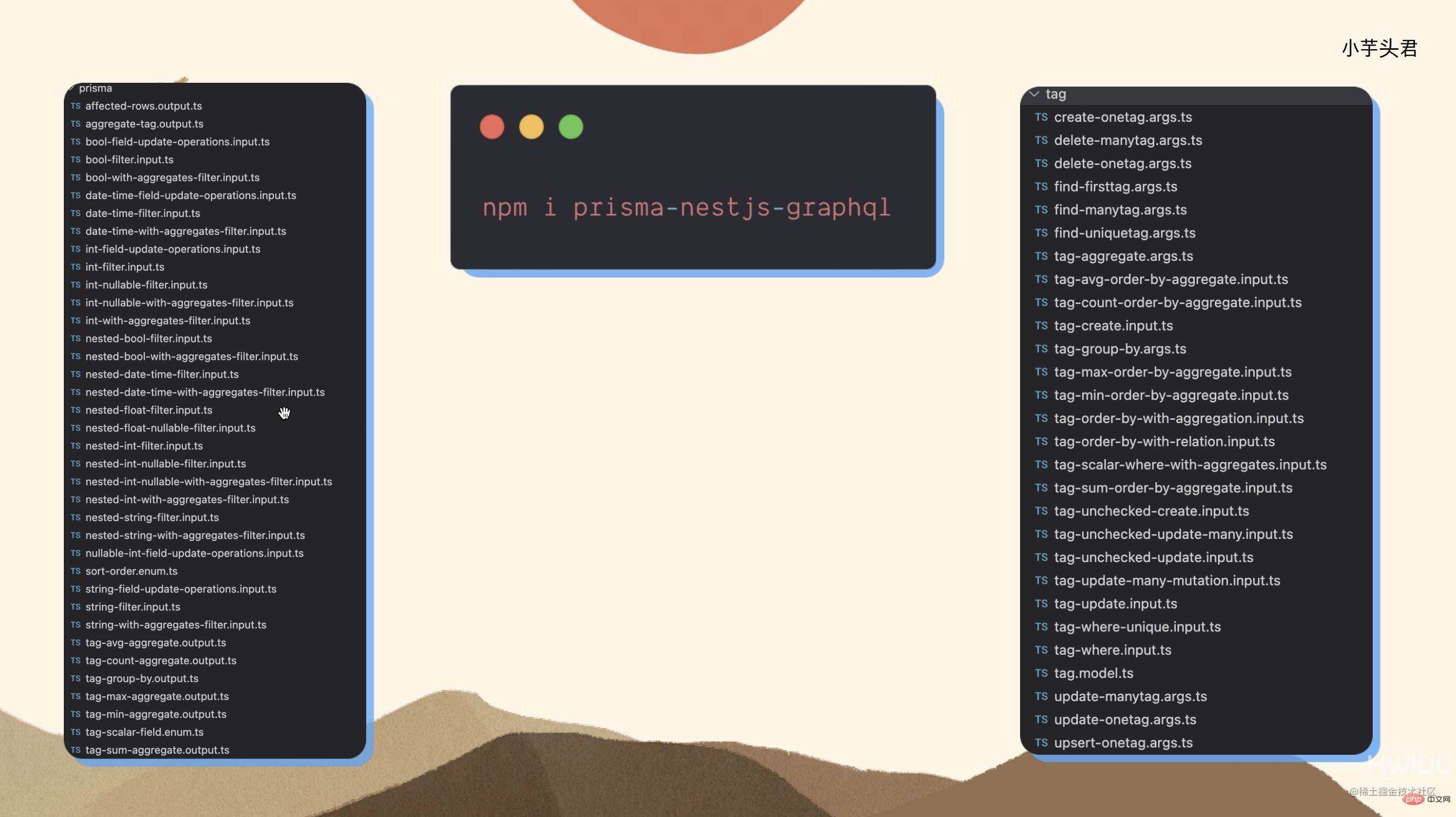
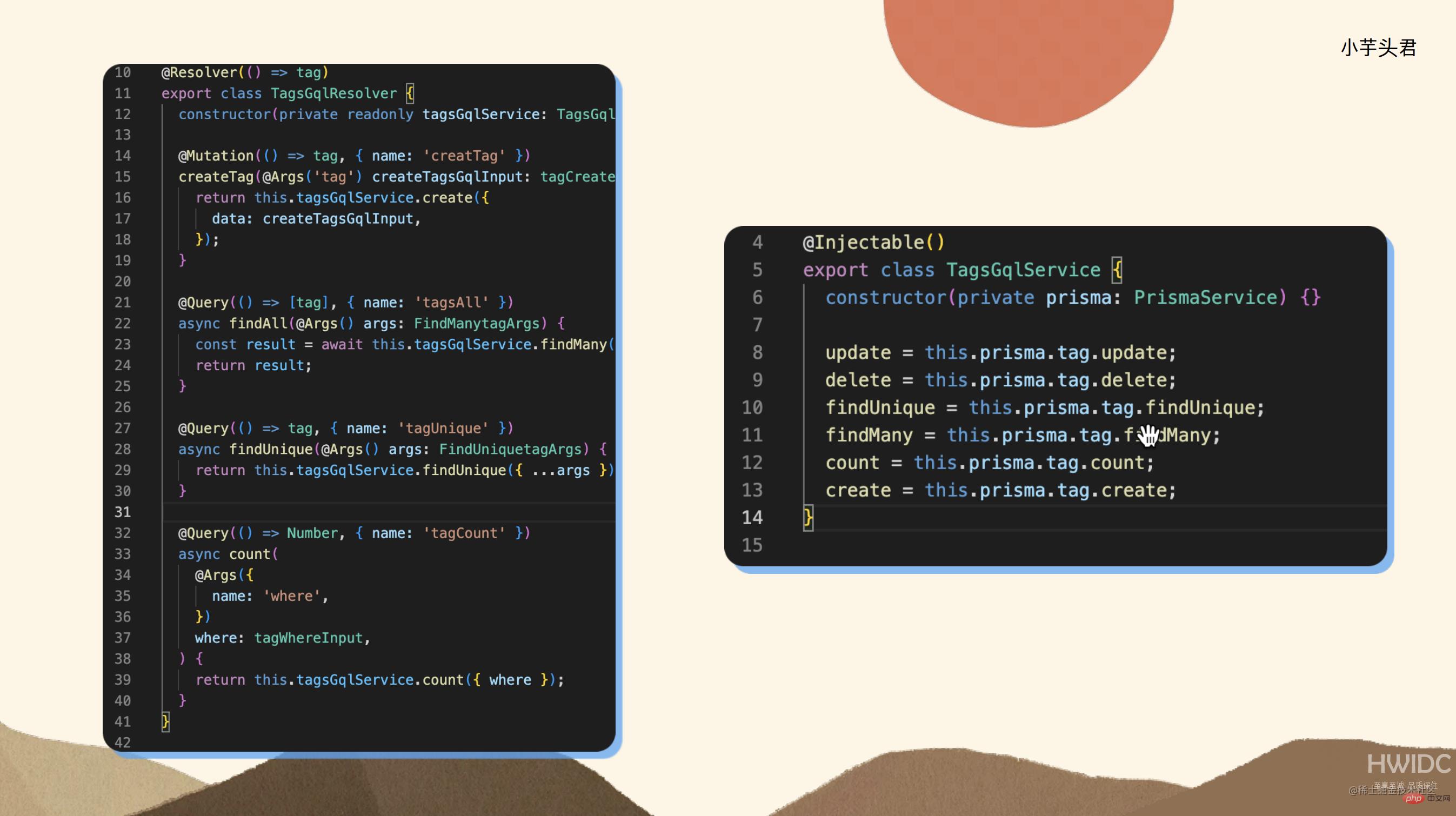
我的查询操作非常灵活,包括了 where 条件、in、order by、group by、count、分页 等操作,而这个工具可以生成这些操作所需的文件。当我生成了这些文件并引入了这个插件后,我的代码就发生了变化。实际上,这就是我在实现增删改查功能的正常代码。
这里 Resolver 实际上是用于 GraphQL 开发的,类似于 Controller 的一个分层,实际上 Resolver 内的逻辑没有发生太大的变化。虽然它与 Controller 的定义有些类似,但是到了 Service 层,你会发现一个神奇的事情,那就是它内部没有代码。在正常的开发中,Service 层通常需要编写调用 ORM 的代码,但在这里,基本上是透传的,你可以直接透传 update、delete、count 等操作。当然,在这里你也可以编写正常的查询操作,但在普通情况下,你只需要透传这些操作 Resolver,Resolver 会直接透传给前端。
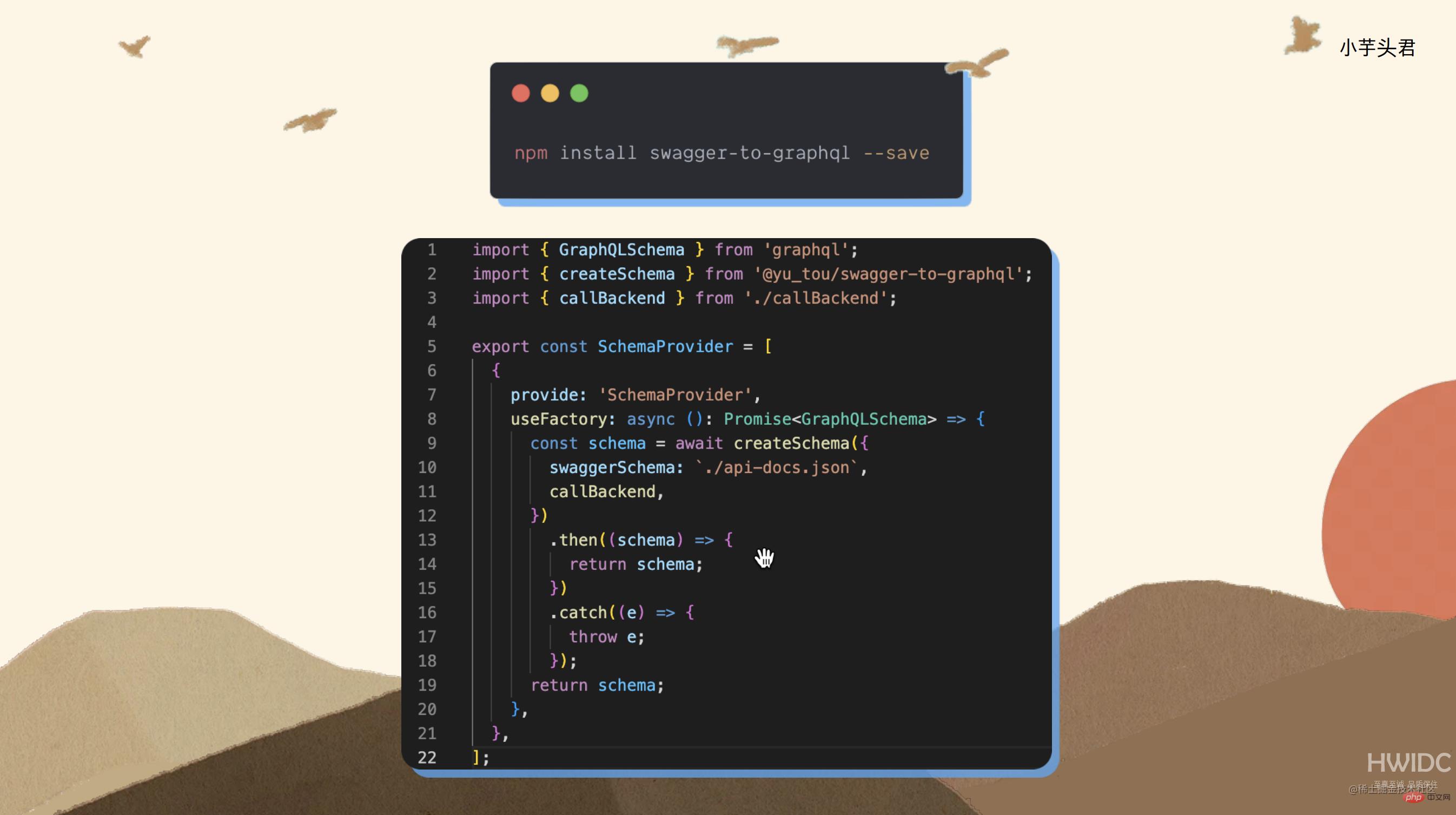
swagger-to-graphql
在实际开发过程中,前端代码还需要访问服务端之前开发的接口。为了使这些接口与前端代码的数据访问更好地结合,需要使用 swagger-to-graphql 工具,它可以将 Swagger 的格式(即 Open API 的标准格式)转换为 Graphql 数据模型,使得前端代码可以直接访问服务端的接口。这个库的使用非常简单,只需传入一个 Swagger 文档,定义一个 Provider,把 Swagger 的数据传进来,就会自动生成一个透传的 GraphQL 接口供使用。可以在 GraphQL 的视图中看到服务端定义的接口以及所有可用的查询参数。
第 63 届早早聊大会 - 低代码无代码,玩转低代码。上车戳:www.zaozao.run/conf/c63