
图文详解Node V8引擎的内存和GC
本篇文章带大家深入了解NodeJS V8引擎的内存和垃圾回收器(GC),希望对大家有所帮助!

一、为什么需要GC
程序应用运行需要使用内存,其中内存的两个分区是我们常常会讨论的概念:栈区和堆区。
栈区是线性的队列,随着函数运行结束自动释放的,而堆区是自由的动态内存空间、堆内存是手动分配释放或者 垃圾回收程序(Garbage Collection,后文都简称GC)自动分配释放的。
软件发展早期或者一些语言对于堆内存都是手动操作分配和释放,比如 C、C++。虽然能精准操作内存,达到尽可能的最优内存使用,但是开发效率却非常低,也容易出现内存操作不当。【相关教程推荐:nodejs视频教程、编程教学】
随着技术发展,高级语言(例如Java Node)都不需要开发者手动操作内存,程序语言自动会分配和释放空间。同时也诞生了 GC(Garbage Collection)垃圾回收器,帮助释放和整理内存。开发者大部分情况不需要关心内存本身,可以专注业务开发。后文主要是讨论堆内存和 GC。
二、GC发展
GC运行会消耗CPU资源,GC运行的过程会触发STW(stop-the-world)暂停业务代码线程,为什么会 STW 呢?是为了保证在 GC 的过程中,不会和新创建的对象起冲突。
GC主要是伴随内存大小增加而发展演化。大致分为3个大的代表性阶段:
- 阶段一 单线程GC(代表:serial)
单线程GC,在它进行垃圾收集时,必须完全暂停其他所有的工作线程 ,它是最初阶段的GC,性能也是最差的
- 阶段二 并行多线程GC(代表:Parallel Scavenge, ParNew)
在多 CPU 环境中利用多条 GC 线程同时并行运行,从而垃圾回收的时间减少、用户线程停顿的时间也减少,这个算法也会STW,完全暂停其他所有的工作线程
- 阶段三 多线程并发 concurrent GC(代表:CMS (Concurrent Mark Sweep) G1)
这里的并发是指:GC多线程执行可以和业务代码并发运行。
在前面的两个发展阶段的 GC 算法都会完全 STW,而在 concurrent GC 中,有部分阶段 GC 线程可以和业务代码并发运行,保证了更短的 STW 时间。但是这个模式就会存在标记错误,因为 GC 过程中可能有新对象进来,当然算法本身会修正和解决这个问题
上面的三个阶段并不代表 GC 一定是上面描述三种的其中一种。不同程序语言的 GC 根据不同需求采用多种算法组合实现。
三、v8 内存分区与GC
堆内存设计与GC设计是紧密相关的。V8 把堆内存分为几大区域,采用分代策略。
盗图:
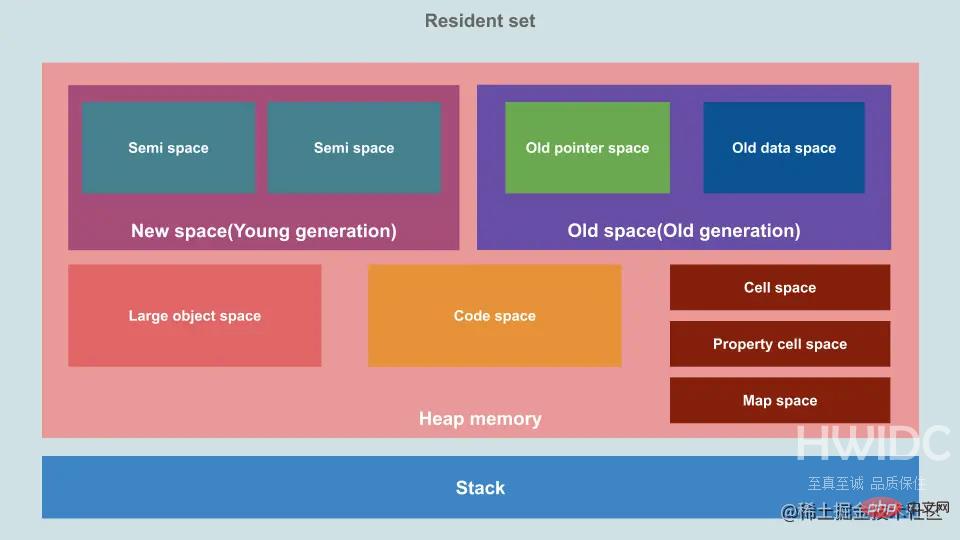
- 新生代(new-space 或 young-generation):空间小,分为了两个半空间(semi-space),其中的数据存活期短。
- 老生代(old-space 或 old-generation):空间大,可增量,其中的数据存活期长
- 大对象空间(large-object-space):默认超过256K的对象会在此空间下,下文解释
- 代码空间(code-space):即时编译器(JIT)在这里存储已编译的代码
- 元空间 (cell space):这个空间用于存储小的、固定大小的JavaScript对象,比如数字和布尔值。
- 属性元空间 (property cell space):这个空间用于存储特殊的JavaScript对象,比如访问器属性和某些内部对象。
- Map Space:这个空间用于存储用于JavaScript对象的元信息和其他内部数据结构,比如Map和Set对象。
3.1 分代策略:新生代和老生代

在 Node.js 中,GC 采用分代策略,分为新、老生代区,内存数据大都在这两个区域。
3.1.1 新生代
新生代是一个小的、存储年龄小的对象、快速的内存池,分为了两个半空间(semi-space),一半的空间是空闲的(称为to空间),另一半的空间是存储了数据(称为from空间)。
当对象首次创建时,它们被分配到新生代 from 半空间中,它的年龄为1。当 from 空间不足或者超过一定大小数量之后,会触发 Minor GC(采用复制算法 Scavenge),此时,GC 会暂停应用程序的执行(STW,stop-the-world),标记(from空间)中所有活动对象,然后将它们整理连续移动到新生代的另一个空闲空间(to空间)中。最后原本的 from 空间的内存会被全部释放而变成空闲空间,两个空间就完成 from 和 to 的对换,复制算法是牺牲了空间换取时间的算法。
新生代的空间更小,所以此空间会更频繁的触发 GC。同时扫描的空间更小,GC性能消耗也更小、它的 GC 执行时间也更短。
每当一次 Minor GC 完成存活的对象年龄就+1,经历过多次Minor GC还存活的对象(年龄大于N),它们将被移动到老生代内存池中。
3.1.2 老生代
老生代是一个大的内存池,用于存储较长寿命的对象。老生代内存采用 标记清除(Mark-Sweep)、标记压缩算法(Mark-Compact)。它的一次执行叫做 Mayor GC。当老生代中的对象占满一定比例时,即存活对象与总对象的比例超过一定的阈值,就会触发一次 标记清除 或 标记压缩。
因为它的空间更大,它的GC执行时间也更长,频率相对新生代更低。如果老生代完成 GC 回收之后空间还是不足,V8 就会从系统中申请更多内存。
可以手动执行 global.gc() 方法,设置不同参数,主动触发GC。 但是需要注意的是,默认情况下,Node.js 是禁用了此方法。如果要启用,可以通过启动 Node.js 应用程序时添加 --expose-gc 参数来开启,例如:
node --expose-gc app.js登录后复制
V8 在老生代中主要采用了 Mark-Sweep 和 Mark-Compact 相结合的方式进行垃圾回收。
Mark-Sweep 是标记清除的意思,它分为两个阶段,标记和清除。Mark-Sweep 在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除未被标记的对象。
Mark-Sweep 最大的问题是在进行一次标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题,因为很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
为了解决 Mark-Sweep 的内存碎片问题,Mark-Compact 被提出来。Mark-Compact 是标记整理的意思,是在 Mark-Sweep 的基础上演进而来的。它们的差别在于对象在标记为死亡后,在整理过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。V8 也会根据一定逻辑,释放一定空闲的内存还给系统。
3.2 大对象空间 large object space
大对象会直接在大对象空间创建,并且不会移动到其它空间。那么到底多大的对象会直接在大对象空间创建,而不是在新生代 from 区中创建呢?查阅资料和源代码终于找到了答案。默认情况下是 256K,V8 似乎并没有暴露修改命令,源码中的 v8_enable_hugepage 配置应该是打包的时候设定的。
chromium.googlesource.com/v8/v8.git/+…
// There is a separate large object space for objects larger than // Page::kMaxRegularHeapObjectSize, so that they do not have to move during // collection. The large object space is paged. Pages in large object space // may be larger than the page size.登录后复制
source.chromium.org/chromium/ch…
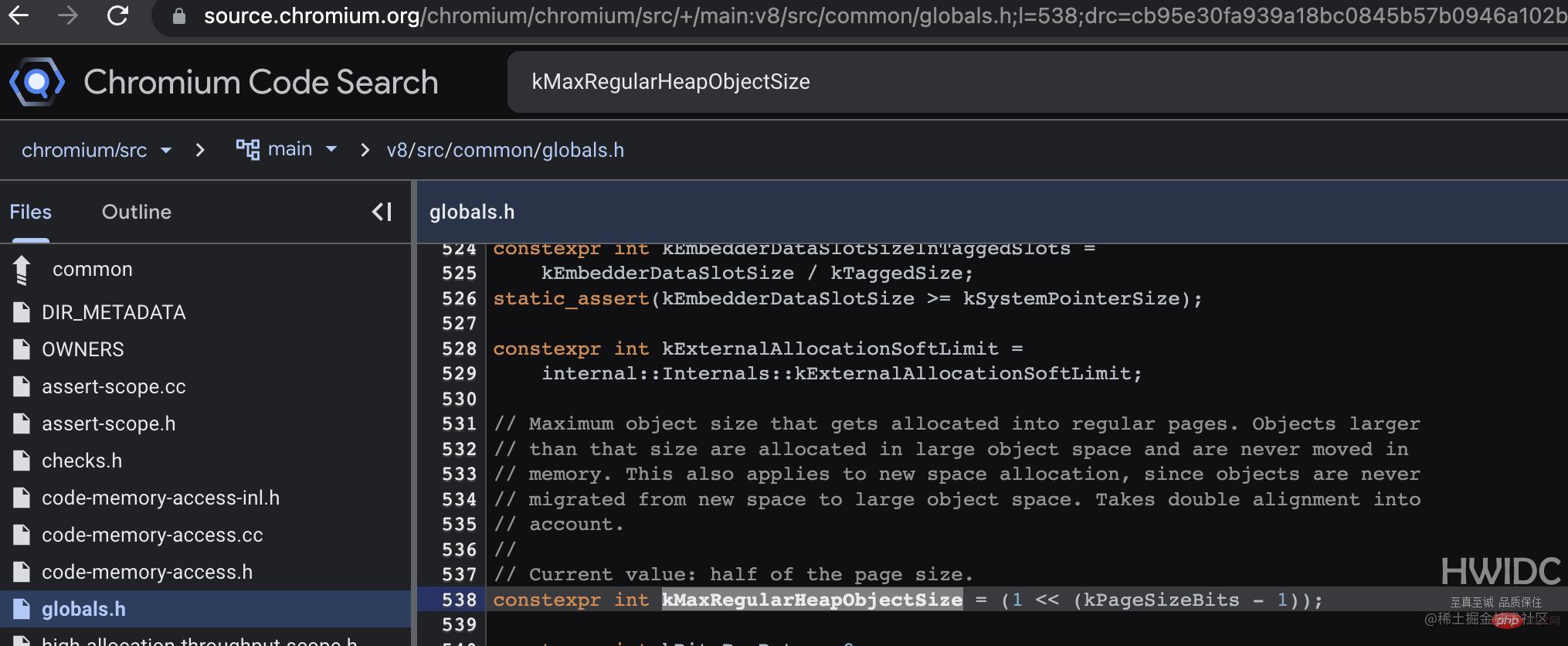
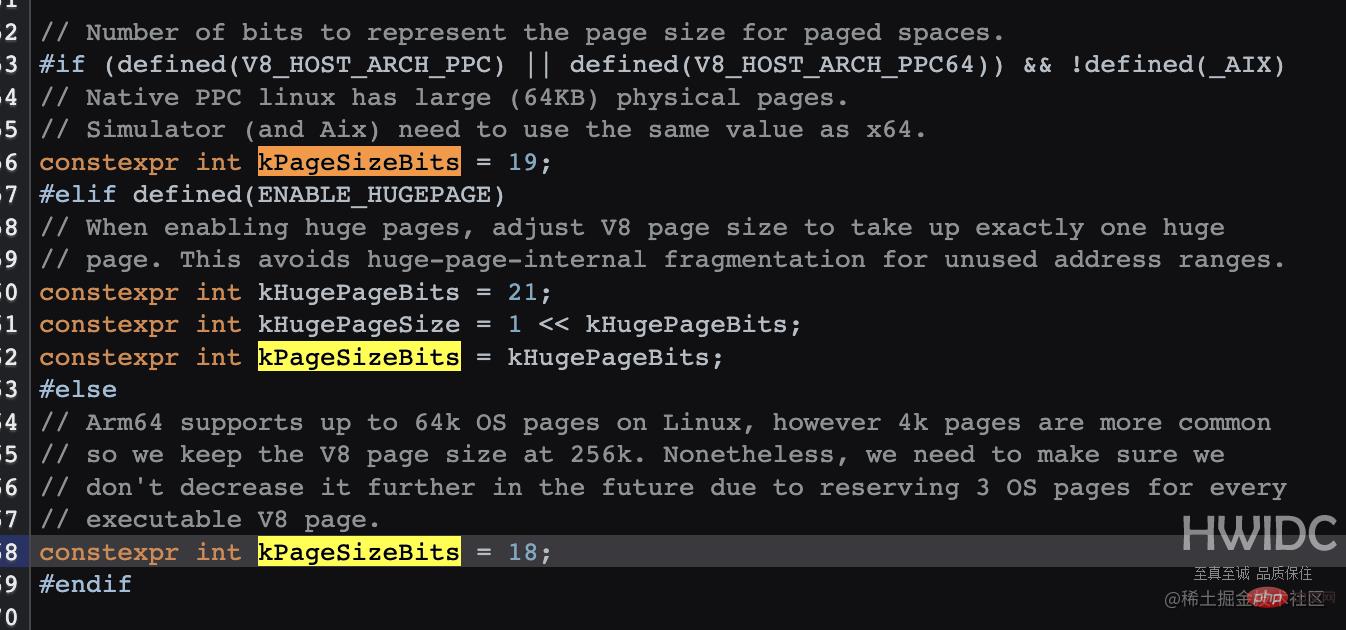
(1 << (18 - 1)) 的结果 256K (1 << (19 - 1)) 的结果 256K (1 << (21 - 1)) 的结果 1M(如果开启了hugPage)登录后复制
四、V8 新老分区大小
4.1 老生代分区大小
在v12.x 之前:
为了保证 GC 的执行时间保持在一定范围内,V8 限制了最大内存空间,设置了一个默认老生代内存最大值,64位系统中为大约1.4G,32位为大约700M,超出会导致应用崩溃。
如果想加大内存,可以使用 --max-old-space-size 设置最大内存(单位:MB)
node --max_old_space_size=登录后复制
在v12以后:
V8 将根据可用内存分配老生代大小,也可以说是堆内存大小,所以并没有限制堆内存大小。以前的限制逻辑,其实不合理,限制了 V8 的能力,总不能因为 GC 过程消耗的时间更长,就不让我继续运行程序吧,后续的版本也对 GC 做了更多优化,内存越来越大也是发展需要。
如果想要做限制,依然可以使用 --max-old-space-size 配置, v12 以后它的默认值是0,代表不限制。
参考文档:nodejs.medium.com/introducing…
4.2 新生代分区大小
新生代中的一个 semi-space 大小 64位系统的默认值是16M,32位系统是8M,因为有2个 semi-space,所以总大小是32M、16M。
--max-semi-space-size
--max-semi-space-size 设置新生代 semi-space 最大值,单位为MB。
此空间不是越大越好,空间越大扫描的时间就越长。这个分区大部分情况下是不需要做修改的,除非针对具体的业务场景做优化,谨慎使用。
--max-new-space-size
--max-new-space-size 设置新生代空间最大值,单位为KB(不存在)
有很多文章说到此功能,我翻了下 nodejs.org 网页中 v4 v6 v7 v8 v10的文档都没有看到有这个配置,使用 node --v8-options 也没有查到,也许以前的某些老版本有,而现在都应该使用 --max-semi-space-size。
五、 内存分析相关API
5.1 v8.getHeapStatistics()
执行 v8.getHeapStatistics(),查看 v8 堆内存信息,查询最大堆内存 heap_size_limit,当然这里包含了新、老生代、大对象空间等。我的电脑硬件内存是 8G,Node版本16x,查看到 heap_size_limit 是4G。
{
total_heap_size: 6799360,
total_heap_size_executable: 524288,
total_physical_size: 5523584,
total_available_size: 4340165392,
used_heap_size: 4877928,
heap_size_limit: 4345298944,
malloced_memory: 254120,
peak_malloced_memory: 585824,
does_zap_garbage: 0,
number_of_native_contexts: 2,
number_of_detached_contexts: 0
}登录后复制到 k8s 容器中查询 NodeJs 应用,分别查看了v12 v14 v16版本,如下表。看起来是本身系统当前的最大内存的一半。128M 的时候,为啥是 256M,因为容器中还有交换内存,容器内存实际最大内存限制是内存限制值 x2,有同等的交换内存。
所以结论是大部分情况下 heap_size_limit 的默认值是系统内存的一半。但是如果超过这个值且系统空间足够,V8 还是会申请更多空间。当然这个结论也不是一个最准确的结论。而且随着内存使用的增多,如果系统内存还足够,这里的最大内存还会增长。
5.2 process.memoryUsage
process.memoryUsage()
{
rss: 35438592,
heapTotal: 6799360,
heapUsed: 4892976,
external: 939130,
arrayBuffers: 11170
}登录后复制通过它可以查看当前进程的内存占用和使用情况 heapTotal、heapUsed,可以定时获取此接口,然后绘画出折线图帮助分析内存占用情况。以下是 Easy-Monitor 提供的功能:
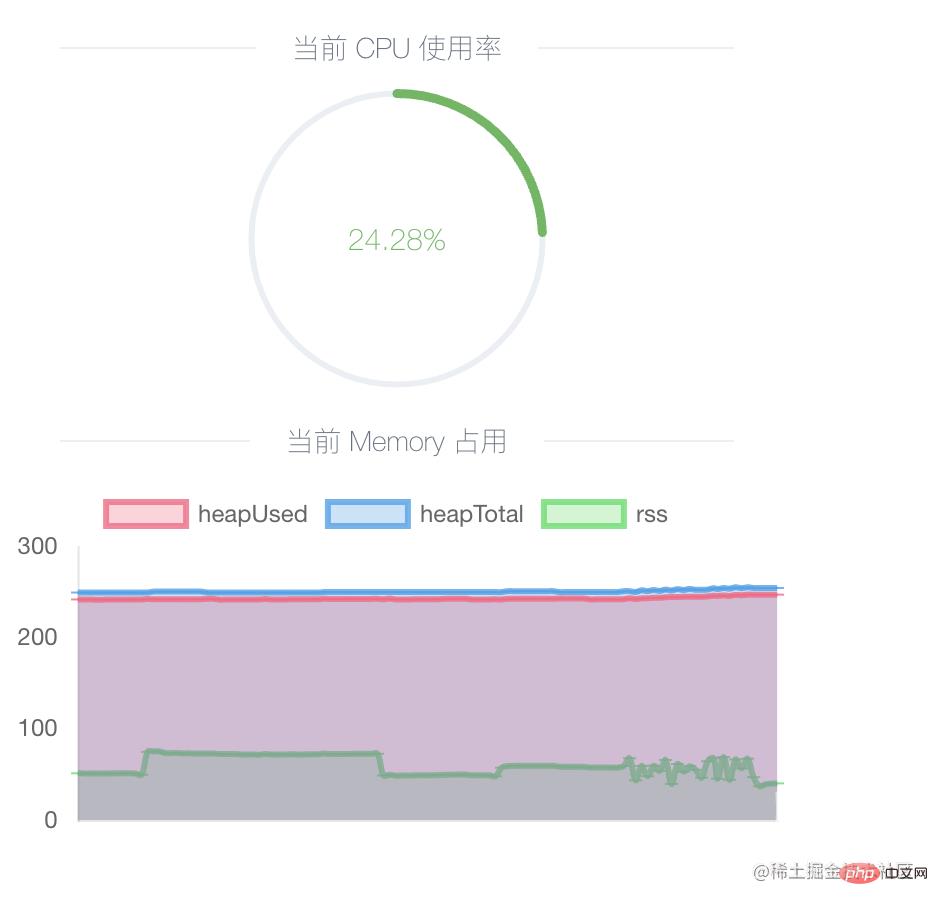
建议本地开发环境使用,开启后,尝试大量请求,会看到内存曲线增长,到请求结束之后,GC触发后会看到内存曲线下降,然后再尝试多次发送大量请求,这样往复下来,如果发现内存一直在增长低谷值越来越高,就可能是发生了内存泄漏。
5.3 开启打印GC事件
使用方法
node --trace_gc app.js
// 或者
v8.setFlagsFromString('--trace_gc');登录后复制- --trace_gc
[40807:0x148008000] 235490 ms: Scavenge 247.5 (259.5) -> 244.7 (260.0) MB, 0.8 / 0.0 ms (average mu = 0.971, current mu = 0.908) task [40807:0x148008000] 235521 ms: Scavenge 248.2 (260.0) -> 245.2 (268.0) MB, 1.2 / 0.0 ms (average mu = 0.971, current mu = 0.908) allocation failure [40807:0x148008000] 235616 ms: Scavenge 251.5 (268.0) -> 245.9 (268.8) MB, 1.9 / 0.0 ms (average mu = 0.971, current mu = 0.908) task [40807:0x148008000] 235681 ms: Mark-sweep 249.7 (268.8) -> 232.4 (268.0) MB, 7.1 / 0.0 ms (+ 46.7 ms in 170 steps since start of marking, biggest step 4.2 ms, walltime since start of marking 159 ms) (average mu = 1.000, current mu = 1.000) finalize incremental marking via task GC in old space requested登录后复制
GCType <heapUsed before> (<heapTotal before>) -> <heapUsed after> (<heapTotal after>) MB登录后复制
上面的 Scavenge 和 Mark-sweep 代表GC类型,Scavenge 是新生代中的清除事件,Mark-sweep 是老生代中的标记清除事件。箭头符号前是事件发生前的实际使用内存大小,箭头符号后是事件结束后的实际使用内存大小,括号内是内存空间总值。可以看到新生代中事件发生的频率很高,而后触发的老生代事件会释放总内存空间。
- --trace_gc_verbose
展示堆空间的详细情况
v8.setFlagsFromString('--trace_gc_verbose');
[44729:0x130008000] Fast promotion mode: false survival rate: 19%
[44729:0x130008000] 97120 ms: [HeapController] factor 1.1 based on mu=0.970, speed_ratio=1000 (gc=433889, mutator=434)
[44729:0x130008000] 97120 ms: [HeapController] Limit: old size: 296701 KB, new limit: 342482 KB (1.1)
[44729:0x130008000] 97120 ms: [GlobalMemoryController] Limit: old size: 296701 KB, new limit: 342482 KB (1.1)
[44729:0x130008000] 97120 ms: Scavenge 302.3 (329.9) -> 290.2 (330.4) MB, 8.4 / 0.0 ms (average mu = 0.998, current mu = 0.999) task
[44729:0x130008000] Memory allocator, used: 338288 KB, available: 3905168 KB
[44729:0x130008000] Read-only space, used: 166 KB, available: 0 KB, committed: 176 KB
[44729:0x130008000] New space, used: 444 KB, available: 15666 KB, committed: 32768 KB
[44729:0x130008000] New large object space, used: 0 KB, available: 16110 KB, committed: 0 KB
[44729:0x130008000] Old space, used: 253556 KB, available: 1129 KB, committed: 259232 KB
[44729:0x130008000] Code space, used: 10376 KB, available: 119 KB, committed: 12944 KB
[44729:0x130008000] Map space, used: 2780 KB, available: 0 KB, committed: 2832 KB
[44729:0x130008000] Large object space, used: 29987 KB, available: 0 KB, committed: 30336 KB
[44729:0x130008000] Code large object space, used: 0 KB, available: 0 KB, committed: 0 KB
[44729:0x130008000] All spaces, used: 297312 KB, available: 3938193 KB, committed: 338288 KB
[44729:0x130008000] Unmapper buffering 0 chunks of committed: 0 KB
[44729:0x130008000] External memory reported: 20440 KB
[44729:0x130008000] Backing store memory: 22084 KB
[44729:0x130008000] External memory global 0 KB
[44729:0x130008000] Total time spent in GC : 199.1 ms登录后复制- --trace_gc_nvp
每次GC事件的详细信息,GC类型,各种时间消耗,内存变化等
v8.setFlagsFromString('--trace_gc_nvp');
[45469:0x150008000] 8918123 ms: pause=0.4 mutator=83.3 gc=s reduce_memory=0 time_to_safepoint=0.00 heap.prologue=0.00 heap.epilogue=0.00 heap.epilogue.reduce_new_space=0.00 heap.external.prologue=0.00 heap.external.epilogue=0.00 heap.external_weak_global_handles=0.00 fast_promote=0.00 complete.sweep_array_buffers=0.00 scavenge=0.38 scavenge.free_remembered_set=0.00 scavenge.roots=0.00 scavenge.weak=0.00 scavenge.weak_global_handles.identify=0.00 scavenge.weak_global_handles.process=0.00 scavenge.parallel=0.08 scavenge.update_refs=0.00 scavenge.sweep_array_buffers=0.00 background.scavenge.parallel=0.00 background.unmapper=0.04 unmapper=0.00 incremental.steps_count=0 incremental.steps_took=0.0 scavenge_throughput=1752382 total_size_before=261011920 total_size_after=260180920 holes_size_before=838480 holes_size_after=838480 allocated=831000 promoted=0 semi_space_copied=4136 nodes_died_in_new=0 nodes_copied_in_new=0 nodes_promoted=0 promotion_ratio=0.0% average_survival_ratio=0.5% promotion_rate=0.0% semi_space_copy_rate=0.5% new_space_allocation_throughput=887.4 unmapper_chunks=124
[45469:0x150008000] 8918234 ms: pause=0.6 mutator=110.9 gc=s reduce_memory=0 time_to_safepoint=0.00 heap.prologue=0.00 heap.epilogue=0.00 heap.epilogue.reduce_new_space=0.04 heap.external.prologue=0.00 heap.external.epilogue=0.00 heap.external_weak_global_handles=0.00 fast_promote=0.00 complete.sweep_array_buffers=0.00 scavenge=0.50 scavenge.free_remembered_set=0.00 scavenge.roots=0.08 scavenge.weak=0.00 scavenge.weak_global_handles.identify=0.00 scavenge.weak_global_handles.process=0.00 scavenge.parallel=0.08 scavenge.update_refs=0.00 scavenge.sweep_array_buffers=0.00 background.scavenge.parallel=0.00 background.unmapper=0.04 unmapper=0.00 incremental.steps_count=0 incremental.steps_took=0.0 scavenge_throughput=1766409 total_size_before=261207856 total_size_after=260209776 holes_size_before=838480 holes_size_after=838480 allocated=1026936 promoted=0 semi_space_copied=3008 nodes_died_in_new=0 nodes_copied_in_new=0 nodes_promoted=0 promotion_ratio=0.0% average_survival_ratio=0.5% promotion_rate=0.0% semi_space_copy_rate=0.3% new_space_allocation_throughput=888.1 unmapper_chunks=124登录后复制5.4 内存快照
const { writeHeapSnapshot } = require('node:v8');
v8.writeHeapSnapshot()登录后复制打印快照,将会STW,服务停止响应,内存占用越大,时间越长。此方法本身就比较费时间,所以生成的过程预期不要太高,耐心等待。
注意:生成内存快照的过程,会STW(程序将暂停)几乎无任何响应,如果容器使用了健康检测,这时无法响应的话,容器可能被重启,导致无法获取快照,如果需要生成快照、建议先关闭健康检测。
兼容性问题:此 API arm64 架构不支持,执行就会卡住进程 生成空快照文件 再无响应, 如果使用库 heapdump,会直接报错:
(mach-o file, but is an incompatible architecture (have (arm64), need (x86_64))
此 API 会生成一个 .heapsnapshot 后缀快照文件,可以使用 Chrome 调试器的“内存”功能,导入快照文件,查看堆内存具体的对象数和大小,以及到GC根结点的距离等。也可以对比两个不同时间快照文件的区别,可以看到它们之间的数据量变化。
六、利用内存快照分析内存泄漏
一个 Node 应用因为内存超过容器限制经常发生重启,通过容器监控后台看到应用内存的曲线是一直上升的,那应该是发生了内存泄漏。
使用 Chrome 调试器对比了不同时间的快照。发现对象增量最多的是闭包函数,继而展开查看整个列表,发现数据量较多的是 mongo 文档对象,其实就是闭包函数内的数据没有被释放,再通过查看 Object 列表,发现同样很多对象,最外层的详情显示的是 Mongoose 的 Connection 对象。
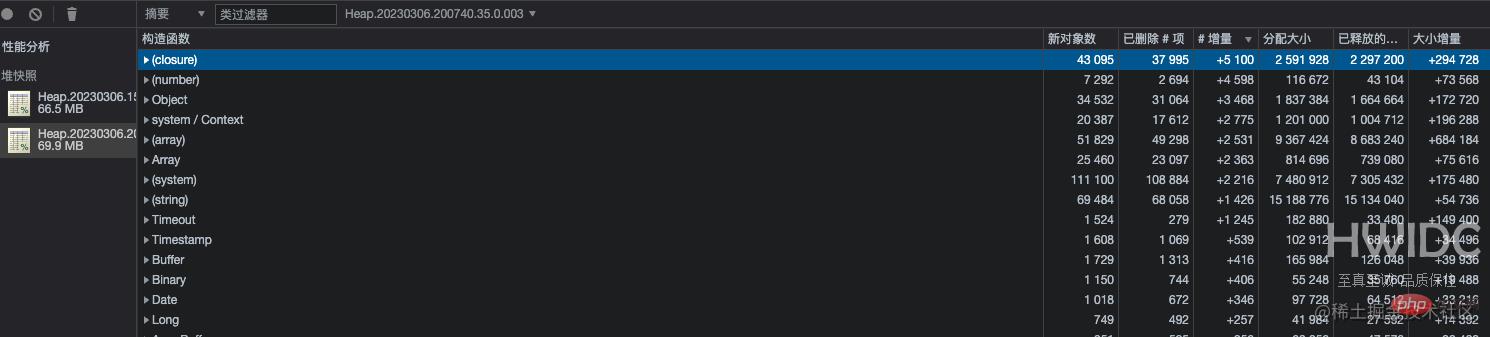
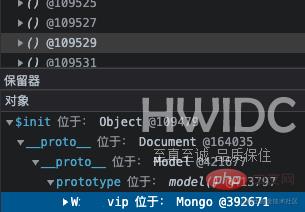
到此为止,已经大概定位到一个类的 mongo 数据存储逻辑附近有内存泄漏。
再看到 Timeout 对象也比较多,从 GC 根节点距离来看,这些对象距离非常深。点开详情,看到这一层层的嵌套就定位到了代码中准确的位置。因为那个类中有个定时任务使用 setInterval 定时器去分批处理一些不紧急任务,当一个 setInterval 把事情做完之后就会被 clearInterval 清除。
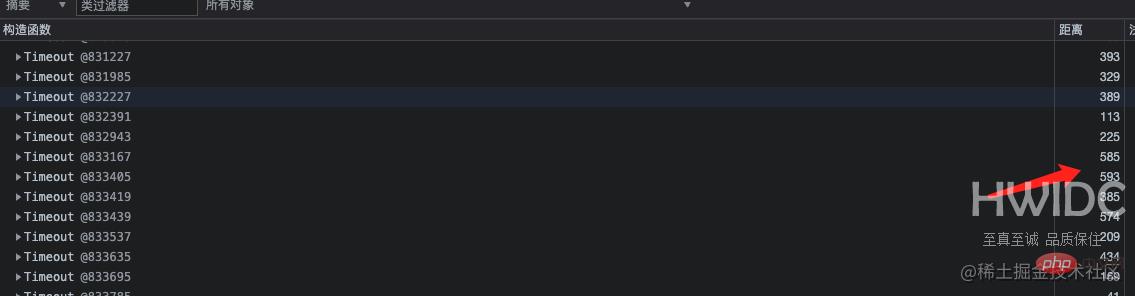
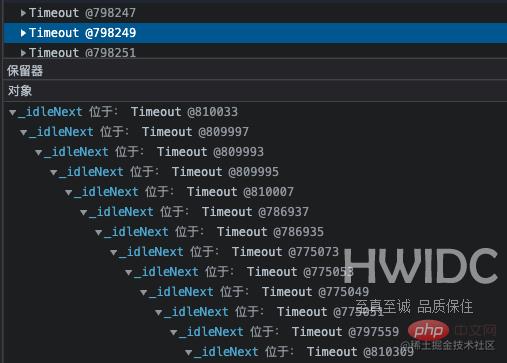
泄漏解决和优化
通过代码逻辑分析,最终找到了问题所在,是 clearInterval 的触发条件有问题,导致定时器没有被清除一直循环下去。定时器一直执行,这段代码和其中的数据还在闭包之中,无法被 GC 回收,所以内存会越来越大直至达到上限崩溃。
这里使用 setInterval 的方式并不合理,顺便改成了利用 for await 队列顺序执行,从而达到避免同时间大量并发的效果,代码也要清晰许多。由于这块代码比较久远,就不考虑为啥当初使用 setInterval 了。
发布新版本之后,观察了十多天,内存平均保持在100M出头,GC 正常回收临时增长的内存,呈现为波浪曲线,没有再出现泄漏。

至此利用内存快照,分析并解决了内存泄漏。当然实际分析的时候要曲折一点,这个内存快照的内容并不好理解、并不那么直接。快照数据的展示是类型聚合的,需要通过看不同的构造函数,以及内部的数据详情,结合自己的代码综合分析,才能找到一些线索。 比如从当时我得到的内存快照看,有大量数据是 闭包、string、mongo model类、Timeout、Object等,其实这些增量的数据都是来自于那段有问题的代码,并且无法被 GC 回收。
六、 最后
不同的语言 GC 实现都不一样,比如 Java 和 Go:
Java:了解 JVM (对应Node V8)的知道,Java 也采用分代策略,它的新生代中还存在一个 eden 区,新生的对象都在这个区域创建。而 V8 新生代没有 eden 区。
Go:采用标记清除,三色标记算法
不同的语言的 GC 实现不同,但是本质上都是采用不同算法组合实现。在性能上,不同的组合,带来的各方面性能效率不一样,但都是此消彼长,只是偏向不同的应用场景而已。
更多node相关知识,请访问:nodejs 教程!