
浅析node怎么实现ocr
怎么实现ocr(光学字符识别)?下面本篇文章给大家介绍一下使用node实现实现实现ocr的方法,希望对大家有所帮助!

ocr即光学字符识别,简单的来说就是把图片上的文字识别出来。
很遗憾我只是一个底层的web程序员?,不咋会AI,要想实现ocr,只能找找第三方库了。
python语言有很多ocr的第三方库,找了很久nodejs实现ocr的第三方库,最后发现了tesseract.js这个库还是能很方便的实现ocr。【相关教程推荐:nodejs视频教程】
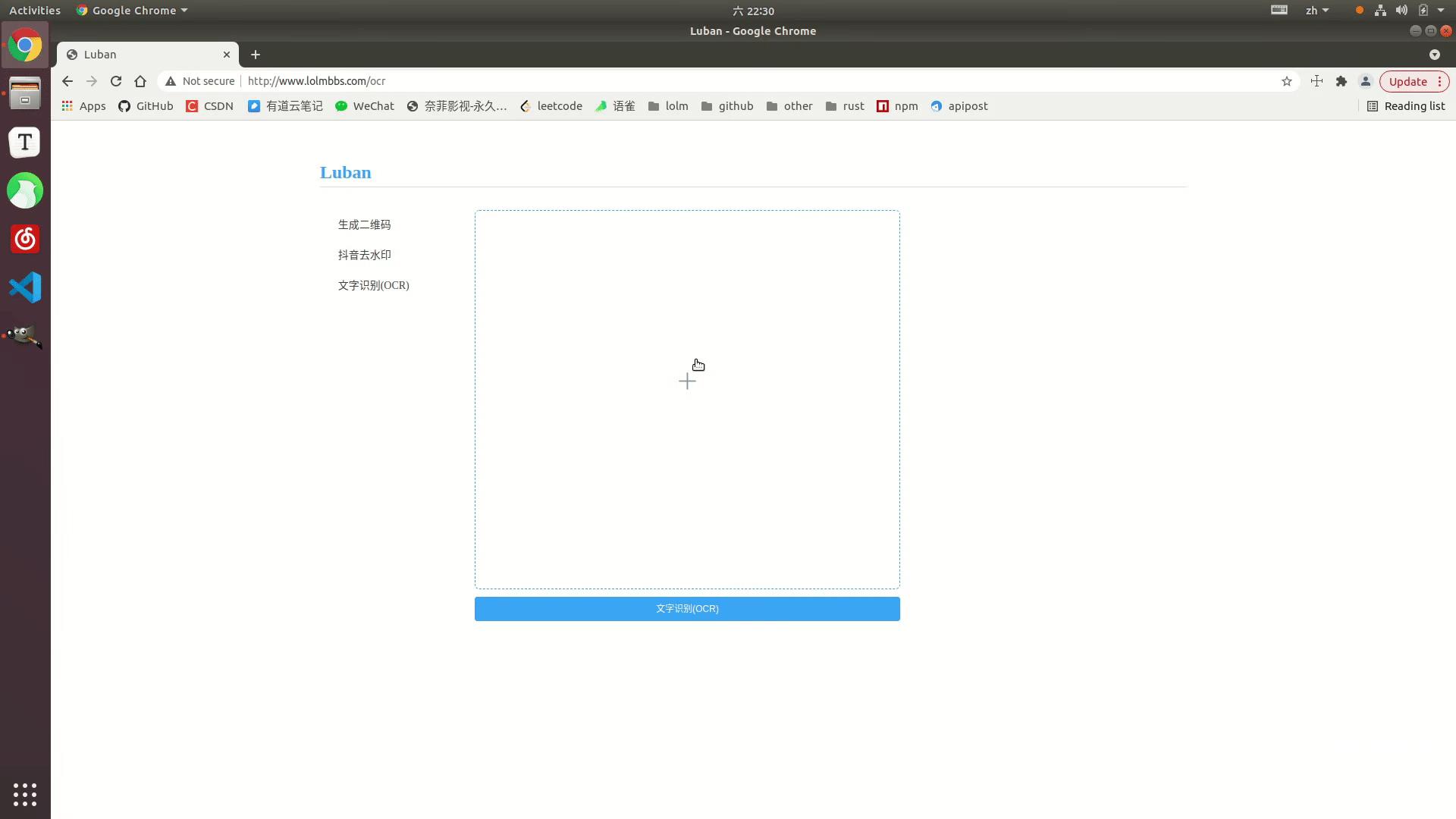
效果展示
在线示例: http://www.lolmbbs.com/tool/ocr
详细代码
tesserract.js 这个库提供了多个版本供选择,我这里使用的是离线的版本tesseract.js-offline,毕竟谁都由网络不好的时候。
默认示例代码
const { createWorker } = require('tesseract.js');
const path = require('path');
const worker = createWorker({
langPath: path.join(__dirname, '..', 'lang-data'),
logger: m => console.log(m),
});
(async () => {
await worker.load();
await worker.loadLanguage('eng');
await worker.initialize('eng');
const { data: { text } } = await worker.recognize(path.join(__dirname, '..', 'images', 'testocr.png'));
console.log(text);
await worker.terminate();
})();登录后复制1. 支持多语言识别
tesseract.js 离线版本默认示例代码只支持识别英文,如果识别中文,结果会是一堆问号。但是幸运的是你可以导入多个训练好的语言模型,让它支持多个语言的识别。
从https://github.com/naptha/tessdata/tree/gh-pages/4.0.0这里下载你需要的对应语言模型,放入到根目录下的lang-data目录下
我这里选择了中(chi_sim.traineddata.gz)日(jpn.traineddata.gz)英(eng.traineddata.gz)三国语言模型。修改代码中加载和初始化模型的语言项配置,来同时支持中日英三国语言。
await worker.loadLanguage('chi_sim+jpn+eng');
await worker.initialize('chi_sim+jpn+eng');登录后复制为了方便大家的测试,我在示例的离线版本,已经放入了中日韩三国语言的训练模型和实例代码以及测试图片。
https://github.com/Selenium39/tesseract.js-offline
2. 提高识别性能
如果你运行了离线的版本,你会发现模型的加载和ocr的识别有点慢。可以通过这两个步骤优化。
web项目中,你可以在应用一启动的时候就加载模型,这样后续接收到ocr请求的时候就可以不用等待模型加载了。
参照Why I refactor tesseract.js v2?这篇博客,可以通过
createScheduler方法添加多个worker线程来并发的处理ocr请求。
多线程并发处理ocr请求示例
const Koa = require('koa')
const Router = require('koa-router')
const router = new Router()
const app = new Koa()
const path = require('path')
const moment = require('moment')
const { createWorker, createScheduler } = require('tesseract.js')
;(async () => {
const scheduler = createScheduler()
for (let i = 0; i < 4; i++) {
const worker = createWorker({
langPath: path.join(__dirname, '.', 'lang-data'),
cachePath: path.join(__dirname, '.'),
logger: m => console.log(`${moment().format('YYYY-MM-DD HH:mm:ss')}-${JSON.stringify(m)}`)
})
await worker.load()
await worker.loadLanguage('chi_sim+jpn+eng')
await worker.initialize('chi_sim+jpn+eng')
scheduler.addWorker(worker)
}
app.context.scheduler = scheduler
})()
router.get('/test', async (ctx) => {
const { data: { text } } = await ctx.scheduler.addJob('recognize', path.join(__dirname, '.', 'images', 'chinese.png'))
// await ctx.scheduler.terminate()
ctx.body = text
})
app.use(router.routes(), router.allowedMethods())
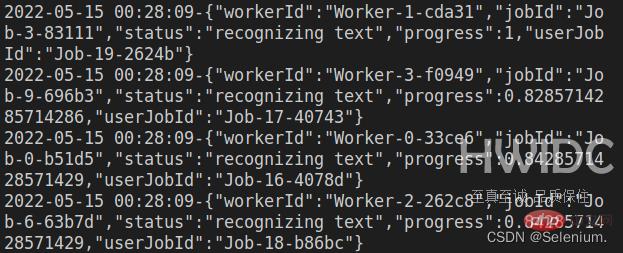
app.listen(3002)登录后复制发起并发请求,可以看到多个worker再并发执行ocr任务
ab -n 4 -c 4 localhost:3002/test
3.前端代码
效果展示中的前端代码主要是用了elementui组件和vue-cropper这个组件实现。
vue-cropper组件具体的使用可以参考我的这篇博客vue图片裁剪:使用vue-cropper做图片裁剪
ps: 上传图片的时候可以先在前端加载上传图片的base64,先看到上传的图片,再请求后端上传图片 ,对用户的体验比较好
完整代码如下
<template>
<div>
<div style="margin-top:30px;height:500px">
<div class="show">
<vueCropper
v-if="imgBase64"
ref="cropper"
:img="imgBase64"
:output-size="option.size"
:output-type="option.outputType"
:info="true"
:full="option.full"
:can-move="option.canMove"
:can-move-box="option.canMoveBox"
:original="option.original"
:auto-crop="option.autoCrop"
:fixed="option.fixed"
:fixed-number="option.fixedNumber"
:center-box="option.centerBox"
:info-true="option.infoTrue"
:fixed-box="option.fixedBox"
:max-img-size="option.maxImgSize"
style="background-image:none"
@mouseenter.native="enter"
@mouseleave.native="leave"
></vueCropper>
<el-upload
v-else
ref="uploader"
class="avatar-uploader"
drag
multiple
action=""
:show-file-list="false"
:limit="1"
:http-request="upload"
>
<i class="el-icon-plus avatar-uploader-icon"></i>
</el-upload>
</div>
<div
class="ocr"
@mouseleave="leaveCard"
>
<el-card
v-for="(item,index) in ocrResult"
:key="index"
class="card-box"
@mouseenter.native="enterCard(item)"
>
<el-form
size="small"
label-width="100px"
label-position="left"
>
<el-form-item label="识别结果">
<el-input v-model="item.text"></el-input>
</el-form-item>
</el-form>
</el-card>
</div>
</div>
<div style="margin-top:10px">
<el-button
size="small"
type="primary"
style="width:60%"
@click="doOcr"
>
文字识别(OCR)
</el-button>
</div>
</div>
</template>
<script>
import { uploadImage, ocr } from '../utils/api'
export default {
name: 'Ocr',
data () {
return {
imgSrc: '',
imgBase64: '',
option: {
info: true, // 裁剪框的大小信息
outputSize: 0.8, // 裁剪生成图片的质量
outputType: 'jpeg', // 裁剪生成图片的格式
canScale: false, // 图片是否允许滚轮缩放
autoCrop: true, // 是否默认生成截图框
fixedBox: false, // 固定截图框大小 不允许改变
fixed: false, // 是否开启截图框宽高固定比例
fixedNumber: [7, 5], // 截图框的宽高比例
full: true, // 是否输出原图比例的截图
canMove: false, // 时候可以移动原图
canMoveBox: true, // 截图框能否拖动
original: false, // 上传图片按照原始比例渲染
centerBox: true, // 截图框是否被限制在图片里面
infoTrue: true, // true 为展示真实输出图片宽高 false 展示看到的截图框宽高
maxImgSize: 10000
},
ocrResult: []
}
},
methods: {
upload (fileObj) {
const file = fileObj.file
const reader = new FileReader()
reader.readAsDataURL(file)
reader.onload = () => {
this.imgBase64 = reader.result
}
const formData = new FormData()
formData.append('image', file)
uploadImage(formData).then(res => {
this.imgUrl = res.imgUrl
})
},
doOcr () {
const cropAxis = this.$refs.cropper.getCropAxis()
const imgAxis = this.$refs.cropper.getImgAxis()
const cropWidth = this.$refs.cropper.cropW
const cropHeight = this.$refs.cropper.cropH
const position = [
(cropAxis.x1 - imgAxis.x1) / this.$refs.cropper.scale,
(cropAxis.y1 - imgAxis.y1) / this.$refs.cropper.scale,
cropWidth / this.$refs.cropper.scale,
cropHeight / this.$refs.cropper.scale
]
const rectangle = {
top: position[1],
left: position[0],
width: position[2],
height: position[3]
}
if (this.imgUrl) {
ocr({ imgUrl: this.imgUrl, rectangle }).then(res => {
this.ocrResult.push(
{
text: res.text,
cropInfo: { //截图框显示的大小
width: cropWidth,
height: cropHeight,
left: cropAxis.x1,
top: cropAxis.y1
},
realInfo: rectangle //截图框在图片上真正的大小
})
})
}
},
enterCard (item) {
this.$refs.cropper.goAutoCrop()// 重新生成自动裁剪框
this.$nextTick(() => {
// if cropped and has position message, update crop box
// 设置自动裁剪框的宽高和位置
this.$refs.cropper.cropOffsertX = item.cropInfo.left
this.$refs.cropper.cropOffsertY = item.cropInfo.top
this.$refs.cropper.cropW = item.cropInfo.width
this.$refs.cropper.cropH = item.cropInfo.height
})
},
leaveCard () {
this.$refs.cropper.clearCrop()
},
enter () {
if (this.imgBase64 === '') {
return
}
this.$refs.cropper.startCrop() // 开始裁剪
},
leave () {
this.$refs.cropper.stopCrop()// 停止裁剪
}
}
}
</script>登录后复制更多node相关知识,请访问:nodejs 教程!
【出处:滨海网站制作公司 http://www.1234xp.com/binhai.html 欢迎留下您的宝贵建议】