
一种编译器视角下的Python性能优化
“Life is short,You need python”!
老码农很喜欢python的优雅,然而,在生产环境中,Python这样的没有优先考虑性能构建优化的动态语言特性可能是危险的,因此,流行的高性能库如TensorFlow 或PyTorch 主要使用python作为一个接口语言,用于与优化后的C/C++库进行交互。
Python 程序的性能优化有很多方法,从编译器视角来看,高性能可以通过嵌入到一个较低层次的、静态可分析的语言中,如C或C++,编译成具有运行时开销较低的本机机器代码,允许它在性能上可以与C/C++相媲美。
Codon就可以看作是这样的一个编译器,利用提前编译、专门的双向类型检查和一种新的双向中间表示,在语言的语法和编译器优化中启用可选的特定领域扩展。它使专业的程序程序员能够以直观、高级和熟悉的方式编写高性能代码。
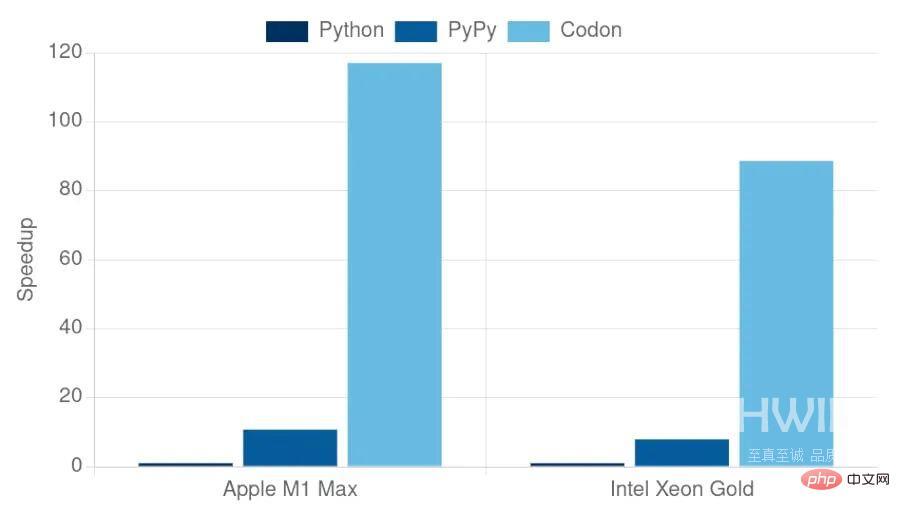
与其他面向性能的Python实现(如PyPy或Numba )不同,Codon是从头开始就作为一个独立的系统,提前编译到静态可执行文件,不用现有的Python运行时(例如,CPython)。因此,在原理上,Codon可以获得更好的性能,并克服特定于Python运行时的问题,如全局解释器锁。在实践中,Codon 将 Python 脚本(像 C 编译器一样)编译成本机代码,运行速度是解释执行时的10到100倍。
1. Codon 简介
Codon是基于Seq语言建模的,Seq是一个生物信息学的DSL。Seq最初被设计为一个金字塔式的DSL,具有许多优点,如易于采用、优异的性能和强大的表达能力。但是,由于严格的类型规则,Seq不支持许多常见的Python语言构造,也没有提供一种机制来轻松地实现新的编译器优化。通过应用双向IR和改进的类型检查器,Codon在Seq的基础上为这些问题提供了一个一般的解决方案。
Codon覆盖了Python大部分的特性,并提供了一个实现特定领域优化的框架。此外,还提供了一个灵活的类型系统,可以更好地处理各种语言特性。该类型系统的类似于RPython 和PyPy 以及静态类型系统。这些想法也被应用于其他动态语言的上下文中,如PRuby。双向IR所使用的方法与前向可插入类型系统有相似之处,例如Java的检查框架。
虽然Codon的中间表达不是第一个可定制的IR,但并不支持所有内容的定制,而是选择一种简单、明确定义的定制,可以与双向性结合来实现更复杂的特性。在结构方面,CIR的灵感来自于LLVM 和Rust的IR。这些IR受益于一个大大简化的节点集和结构,这反过来又简化了IR通道的实现。然而,在结构上,那些实现方法要从根本上重组源代码,消除必须重构才能执行转换的语义信息。为了解决这一缺点,Taichi 都采用了维护控制流和语义信息的层次结构,以增加复杂性为代价。然而,与Codon不同的是,这些IR在很大程度上与它们的语言的前端无关,这使得维护类型的正确性和生成新的代码有些不切实际,甚至不可能实现。因此,CIR利用这些方法的简化层次结构,维护源代码的控制流节点并完全减少的内部节点子集。重要的是,它以双向性增强了这种结构,使新的IR易于生成和操作。
2. 类型检查和推断
Codon利用静态类型检查并编译成LLVM IR,而不使用任何运行时类型信息,类似于之前在动态语言如Python的上下文中进行端到端类型检查的工作。为此,Codon附带了一个静态双向类型系统,称为LTS-DI,该系统利用HindleyMilner风格的推断来推断程序中的类型,而不需要用户手动注释类型(这种做法虽然可以支持,但在Python开发人员中并不普遍)。
由于Python的语法和常见的Pythonic习惯用法的特性,LTS-DI对标准的类似hm的推理进行了调整,以支持显著的Python构造,如理解、迭代器、生成器、复杂函数操作、变量参数、静态类型检查等等。为了处理这些结构和许多其他结构,LTS-DI依赖于:
- 单态化(为每个输入参数的组合实例化一个函数的单独版本)
- 本地化(将每个函数作为一个孤立的类型检查单元)
- 延迟实例化(函数实例化被延迟,直到所有函数参数都已知)。
许多Python构造还需要编译时的表达式(类似于C++的压缩pr表达式),密码子支持该表达式。虽然这些方法在实践中并不少见(例如., C++的模板使用单一化),而延迟实例化已经在HMF类型系统中使用,我们不知道它们在类型检查Python程序的上下文中的联合使用。最后,请注意,Codon的类型系统在其当前实现中是完全静态的,不执行任何运行时类型推论;因此,一些Python特性,如运行时多态性或运行时反射,不受支持。在科学计算的背景下,发现去掉这些特征代表了效用和性能之间的合理折衷。
3. 中间表达
许多语言以一种相对直接的方式编译:源代码被解析为抽象语法树(AST),通常在LLVM 等框架的帮助下,优化并转换为机器代码。虽然这种方法相对容易实现,但通常AST包含的节点类型比表示给定程序所需的要多得多。这种复杂性可能会使实现优化、转换和分析变得困难,甚至不切实际。另一种方法是在执行优化传递之前将AST转换为中间表达(IR),中间表达通常包含一组定义良好语义的简化节点,使它们更有利于转换和优化。
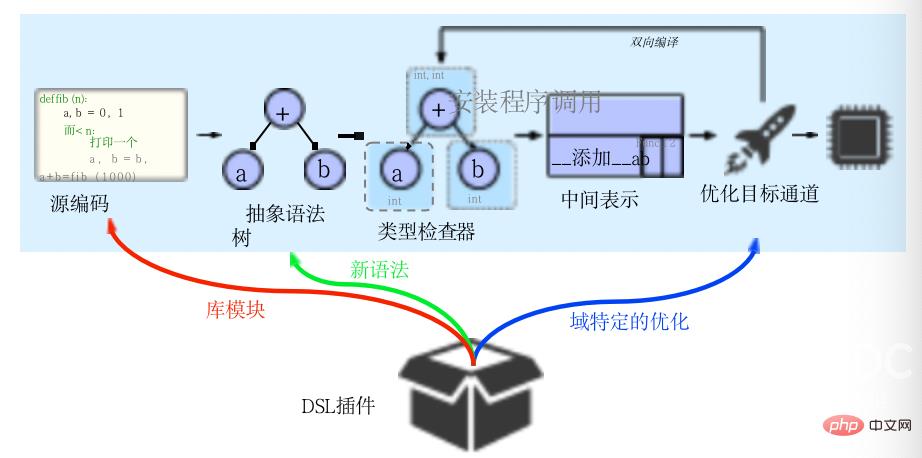
Codon在其IR中实现了这种方法,该IR位于类型检查和优化阶段之间,如上图所示。Codon的中间表达(CIR)比AST要简单得多,其结构更简单,节点类型也更少。尽管如此简单,Codon的中间表达还是维护了源代码的大部分语义信息,并促进“渐进式降低”,从而能够在多个抽象层次上实现优化。
3.1 源码映射
CIR部分灵感来自于LLVM 的IR。在LLVM中,采用了一种类似于单一静态分配(SSA)形式的结构,区分在一个位置分配的值和变量,它们在概念上与内存位置相似,编译首先以线性方式进行,其中源代码被解析为抽象语法树,在该树上执行类型检查以生成中间表达。然而,与其他编译框架不同的是,Codon是双向的,IR优化可以返回到类型检查阶段来生成新的原始程序中没有的节点。该框架是“领域可扩展的”,一个“DSL插件”由库模块、语法和特定领域的优化组成。
为了实现源代码结构的映射,一个值可以嵌套到任意大的树中。例如,这种结构使CIR可以轻松地降低为一个控制流程图。然而,与LLVM不同的是,CIR最初使用被称为流的显式节点来表示控制流,允许与源代码进行密切的结构对应。显式地表示控制流层次结构类似于Taichi所采用的方法。重要的是,这使得依赖于控制流的精确概念的优化和转换更容易实现。一个简单的例子是流,它在CIR中保持显式循环,并允许codon轻松识别循环的常见模式,而不是像在LLVM IR所做的那样解读分支迷宫。
3.2 操作符
CIR并不显式地表示像“+”这样的操作符,而是将它们转换为相应的函数调用。这可以实现任意类型的无缝操作符重载,其语义与Python的相同。例如,+操作符解析为一个add调用。
这种方法产生的一个自然问题是如何为int和浮点数等原始类型实现运算符。Codon通过@llvm函数注释允许内联LLVM IR来解决这个问题,这使所有的原始操作符都可以用codon源代码编写。关于可交换性和结合性等算子属性的信息可以被传递为IR中的注释。
3.3双向IR
传统的编译管道在其数据流中是线性的:源代码被解析为AST,通常转换为IR,优化,最后转换为机器代码。Codon引入了双向IR的概念,其中IR通道能够返回到类型检查阶段,生成新的IR节点和源程序中不存在的专专有化节点。其好处包括:
- 大部分复杂的转换可以直接在codon中实现。例如,预取优化涉及一个通用的动态程序调度器,纯粹在Codon IR中实现是不现实的。
- 可以按需生成用户定义的数据类型的新实例化。例如,需要使用Codon字典的优化可以为适当的键和值类型实例化为Dict类型。实例化类型或函数是一个非常简单的过程,由于级联实现和专有化,它需要完全重新调用类型检查器。
同样地,IR通道本身也可以是通用的,使用Codon的表达类型系统来对各种类型进行操作。IR类型没有相关的泛型(不像AST类型)。但是,每个CIR类型都携带一个对用于生成它的AST类型的引用,以及任何AST泛型类型参数。这些关联的AST类型在重新调用类型检查器时使用,并允许对CIR类型查询它们的底层泛型。请注意,CIR类型对应于高层次抽象;LLVM IR类型更低,并不直接映射到Codon类型。
事实上,在CIR传递期间,实例化新类型的能力对许多CIR操作至关重要。例如,从给定的CIR值x和y创建一个元组(x,y)需要实例化一个新的元组类型元组[X,Y](其中大写标识符为表达类型),这反过来需要实例化新的元组运算符来进行等式和不等式检查、迭代、哈希等等。然而,调回类型检查器使这成为一个无缝的过程。

上图是一个简单的斐波那契函数到CIR源码映射的例子。该函数fib映射到一个具有单个整数参数的CIR BodiedFunc。主体包含一个If控制流,它返回一个常量或递归地调用该函数来获得结果。注意,像+这样的操作符被转换为函数调用(例如,add),但是IR在其结构中映射为原始源代码,允许简单的模式匹配和转换。在这种情况下,只需简单地重载Call的处理程序,检查函数是否符合替换的条件,如果匹配则执行操作。用户还可以定义自己的遍历方案,并随意修改IR结构。
3.4 通道和转换
CIR提供了一个全面的分析和转换基础设施:用户使用各种CIR内置的应用程序类编写通行证,并向密码管理器注册它们,其中更复杂的通道可以利用CIR的双向性,并重新调用类型检查器,以获得新的CIR类型、函数和方法,其示例如下图所示。
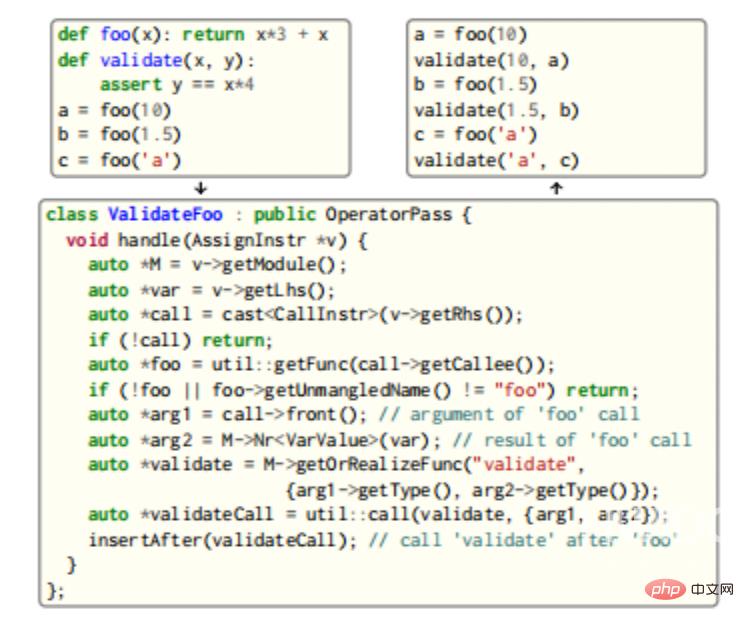
在本示例中,将搜索函数foo的调用,并在每个调用之后插入一个用来验证foo的参数及其输出的调用。由于这两个函数都是通用的,因此将重新调用类型检查器以生成三个新的、唯一的验证实例化。实例化新的类型和函数需要处理可能的专门化和实现其他节点(例如,在示例中实现验证的过程中必须实现==操作符方法__eq__),以及缓存实现以供以后使用。
3.5代码的生成和执行
Codon使用LLVM来生成原生代码。从Codon IR到LLVM IR的转换通常是一个简单的过程。大多数Codon 类型也可以直观地转换为LLVM IR类型:int变成i64,浮子变成双倍,bool变成int8,以此类推——这些转换也允许C/C++的互操作性。元组类型被转换为包含适当元素类型的结构类型,这些元素类型通过值传递(注,元组在Python中是不可变的);这种处理元组的方法允许LLVM在大多数情况下完全优化它们。引用类型,如列表、Dict等,是实现为动态分配的对象,通过引用传递,这些遵循Python的可变语义类型,可以根据需要将类型升级为可选类型来处理无值;可选类型是通过LLVM的i1类型和底层类型的一个元组来实现的,其中前者指示可选类型是否包含一个值。引用类型上的选项专门用于使用空指针来指示缺失的值。
生成器是Python中流行的一种语言构造;事实上,每个for循环都在生成器进行迭代。重要的是,Codon中的生成器不携带额外的开销,并且尽可能编译成等价的标准C代码。为此,Codon使用LLVM协程来实现生成器。
Codon在执行代码时使用了一个小的运行时库。特别是,Boehm垃圾收集器用于管理已分配的内存。Codon提供了两种编译模式:调试和发布。调试模式包括完整的调试信息,允许程序使用GDB和LLDB等工具进行调试,还包含包含文件名和行号的完整回溯信息。发布模式执行了更多的优化(包括从GCC/Clang中进行的-O3优化),并省略了一些安全性和调试信息。因此,用户可以使用调试模式进行快速编程和调试周期,并使用发布模式进行高性能部署。
3.6可扩展性
由于框架的灵活性和双向IR,以及Python语法的整体表达性,Codon应用程序通常在源代码本身中实现特定领域组件的大部分功能。一种模块化的方法可以打包为动态库和Codon源文件。在编译时,密码子编译器可以加载该插件。
一些框架,如MLIR,是允许定制的。另一方面,Condon IR,限制了一些类型的节点,并依赖于双向性来实现进一步的灵活性。特别是,CIR允许用户从“自定义”类型、流、常量和指令中派生出来,这些类型通过声明性接口与框架的其他部分进行交互。例如,自定义节点来自适当的自定义基类(自定义类型、自定义流等),并公开一个“构建器”来构造相应的LLVM IR。实现自定义类型和节点涉及到定义一个通过虚拟方法生成(e。g.构建类型);自定义类型类本身定义了一个方法getBuilder来获取此生成器的实例。这种节点的标准化构造能够与现有的通道和分析无缝地工作。
4应用程序
4.1 基准性能
许多标准的Python程序已经开箱即用,可以很容易地优化Python代码中常见的几种模式,例如字典更新(可以优化为使用单个查找而不是两个),或连续的字符串添加(可以折叠成单个连接以减少分配开销)。

上图显示了Codon的运行时性能,以及CPython(v3.10)和PyPy(v7.3)的性能,在基准测试上,限制为一组“核心”基准测试,不依赖于外部库。与CPython和PyPy相比,Codon总是更快,有时是一个数量级。虽然基准测试是一个不错的性能指标,但它们并非没有缺点,而且往往不能说明整个问题。Codon允许用户为各种领域编写简单的Python代码,同时在实际应用程序和数据集上提供高性能。
4.2 OpenMP:任务和循环的并行性
因为Codon是独立于现有的Python运行时而独立构建的,所以它不受CPython全局解释器锁的影响,因此可以充分利用多线程。为了支持并行编程,Codon的一个扩展允许最终用户使用OpenMP。
对于OpenMP,并行循环的主体被概述为一个新的函数,然后由OpenMP运行时进行多个线程调用。例如,下图中的循环主体将被概述为一个函数f,它将变量a、b、c和循环变量i作为参数。
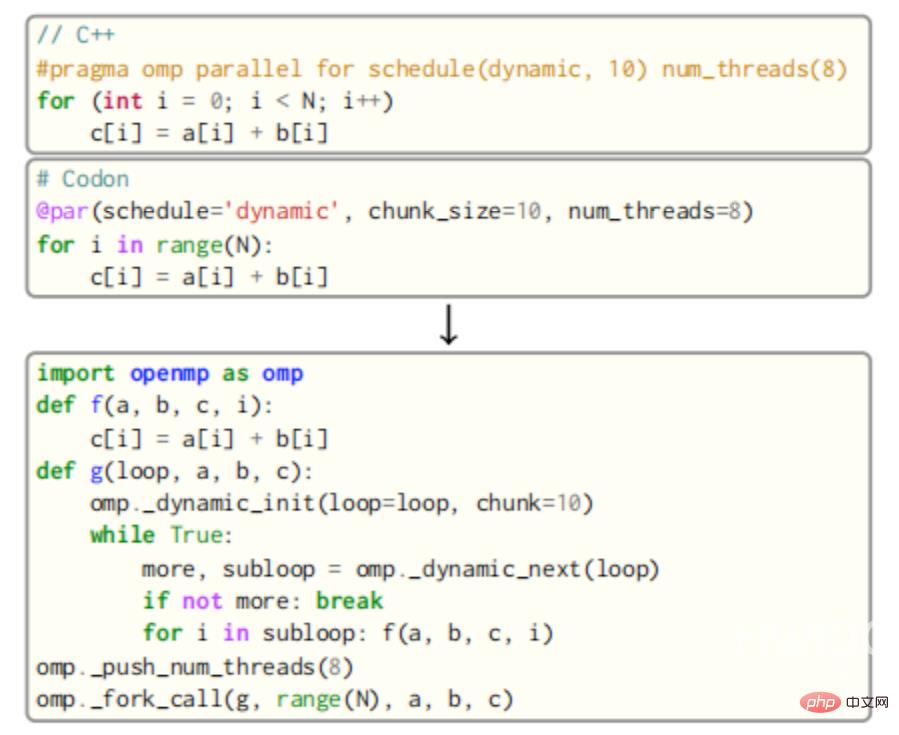
然后,对f的调用将被插入到一个新的函数g中,该函数g调用块大小为10的OpenMP的动态循环调度例程。最后,队列中的所有线程都将通过OpenMP的fork_call函数调用g。结果显示在上图的正确代码片段中,还特别注意处理私有变量以及共享变量。对变量的减少还需要为原子操作(或使用锁)进行额外的代码生成,以及一个额外的OpenMP API调用层。
Codon的双向编译是OpenMP传递的关键组成部分。各种循环的“模板”都是在Codon源代码中实现的。在代码分析之后,通过填充循环体、块大小和调度、重写依赖于共享变量的表达式等,传递副本并专有化这些“模板”。这种设计极大地简化了传递的实现,并增加了一定程度的通用性。
与Clang或GCC不同,Codon的OpenMP通道可以推导出哪些变量是共享的,哪些是私有的,以及正在发生的任何缩减的代码。自定义缩减可以简单地通过提供一个适当的原子魔法方法(例如.aborom_add)的还原类型。Codon通过生成器(Python循环的默认行为)迭代到“命令式循环”,即带有开始、停止和步长值的c式循环。如果存在@par标签,则强制循环将被转换为OpenMP并行循环。非强制式并行循环通过为每个循环迭代生成一个新的OpenMP任务,并在循环之后放置一个同步点来并行化。该方案允许所有Pythonfor-循环被并行化。
OpenMP的转换被实现为一组CIR与@par属性标记的for循环相匹配,并将这些循环转换为CIR中适当的OpenMP构造。几乎所有的OpenMP结构都是作为Condon本身的高阶函数实现。
4.3 CoLa:一个用于基于块压缩的DSL
CoLa是一种基于Codon的DSL,主要针对基于块的数据压缩,这是目前使用的许多常用图像和视频压缩算法的核心。这些类型的压缩很大程度上依赖于将像素区域划分为一系列越来越小的块,形成一个多维数据层次结构,其中每个块需要知道其相对于其他块的位置。例如,H.264视频压缩将输入帧分割成一系列16x16像素块,每个像素分割成8x8像素块,然后将这些像素分割成4x4像素块。跟踪这些单独的像素块之间的位置需要大量的信息数据,这很快就掩盖了现有实现中的底层算法。
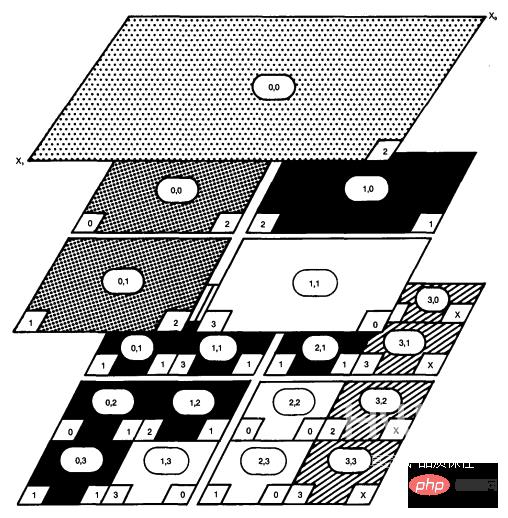
CoLa引入了层级多维数组(HMDA)抽象,它简化了分层数据的表达和使用。HMDA表示具有位置概念的多维数组,它跟踪任何给定的HMDA相对于某个全局坐标系的原点。HMDA还可以跟踪它们的尺寸和步幅。有了这三条数据,任何HMDA都可以确定其在程序中任何一点相对于任何其他HMDA的位置。CoLa将Codon中的HMDA抽象作为一个围绕两种新数据类型为中心的库:块和视图。块创建并拥有一个底层的多维数组,而视图则指向块的特定区域。CoLa公开了两个主要的层次结构——构造操作、位置复制和分区,它们分别创建块和视图。CoLa支持使用整数和切片索引的标准索引,但也引入了两种独特的索引方案,它模拟了压缩标准如何描述数据访问。“越界”索引允许用户访问视图周围的数据,而“托管”索引允许用户使用另一个HMDA对一个HMDA进行索引。
虽然Codon的物理特性和CoLa的抽象结合为用户提供了高级语言和特定于压缩的抽象优势,但由于需要额外的索引操作,HMDA抽象带来了显著的运行时开销。对于压缩,许多HMDA访问发生在计算的最内层,因此在访问原始数组之上的任何额外计算都被证明对运行时有害。CoLa利用Codon框架来实现层次结构,减少了创建的中间视图数量,并且传播试图推断任何给定HMDA的位置。这减少了层次结构的总体大小,并简化了实际的索引计算。在没有这些优化的情况下,CoLa比JPEG和H.264]的参考C代码在速度上平均要慢48.8×、6.7×和20.5×。经过优化后,性能有了极大提升,相对于相同的参考代码,平均运行时间分别为1.06×、0.67×和0.91×。
CoLa是作为一个Codon插件实现的,因此,附带了一个压缩原语库,以及一组CIR和LLVM通道,这些通道优化了创建和访问例程。CoLa还使用Codon提供的自定义数据结构访问语法和操作符,简化了公共索引和缩减操作。
5. 小结
本质上,codon是一个领域可配置的框架,用于设计和快速实现DSL。通过应用一种专门的类型检查算法和新的双向IR算法,可以使各种领域的动态代码易于优化。与直接使用Python相比,Codon可以在不影响高级简单性的情况下匹配C/C++性能。
目前,Codon有几个不支持的Python特性,主要包括运行时多态性、运行时反射和类型操作(例如,动态方法表修改、类成员的动态添加、元类和类装饰器),标准Python库覆盖也存在差距。虽然Codon 编译Python可以作为限制限制性解决方案方案存在,但非常值得关注。
【参考资料与关联阅读】
- https://www.php.cn/link/a7453a5f026fb6831d68bdc9cb0edcae
- https://www.php.cn/link/c49e446a46fa27a6e18ffb6119461c3f
- PyPy’s Tracing JIT Compiler,https://doi.org/10.1145/1565824.1565827
- A Type-Based Multi-stage Programming Framework for Code Generation in C++,https://doi.org/10.1109/CGO51591. 2021.9370333
- https://www.php.cn/link/9fd5e502c1640f62738c8a908d3eb0f7
- LLVM: a compilation framework for lifelong program analysis transformation,https://doi.org/10.1109/CGO.2004.1281665
- AnyDSL: A Partial Evaluation Framework for Programming High-Performance Libraries,https://doi.org/10.1145/3276489
- A Python-based programming language for high-performance computational genomics,https: //doi.org/10.1038/s41587-021-00985-6
- A Compiler for High-Performance Pythonic Applications and DSLs,https://dl.acm.org/doi/abs/10.1145/3578360.3580275
- https://www.php.cn/link/6c7de1f27f7de61a6daddfffbe05c058
- Taichi: A Language for High-Performance Computation on Spatially Sparse Data Structures,https://doi.org/10.1145/3355089. 335650
- https://www.php.cn/link/ca5150ff1c65880ded50f92ed067c95e
- 操作系统中的系统抽象
- 温故知新:从计算机体系结构看操作系统
- 从操作系统看Docker
- 感知人工智能操作系统
- 嵌入式Linux的网络连接管理
- Linux 内核裁剪框架初探
- 机器学习系统架构的10个要素
以上就是一种编译器视角下的Python性能优化的详细内容,更多请关注海外IDC网其它相关文章!
【文章转自:防御服务器 http://www.558idc.com/aqt.html提供,感恩】