
MySQL子查询如何使用
相关子查询
相关子查询执行流程
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 。在主查询的每一行执行时,相关子查询会按照逐行顺序依次执行。
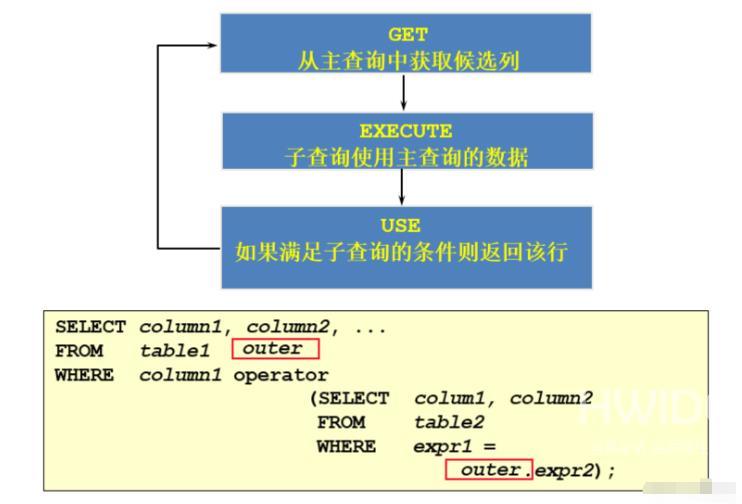
说明:子查询中使用主查询中的列
题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
方式一:相关子查询

在 FROM 中使用子查询
SELECT last_name,salary,e1.department_id FROM employees e1,(SELECT department_id,AVG(salary) dept_avg_sal FROM employees GROUP BY department_id) e2 WHERE e1.`department_id` = e2.department_id AND e2.dept_avg_sal < e1.`salary`;登录后复制
from型的子查询:子查询是作为from的一部分,子查询要用()引起来,并且要给这个子查询取别
名, 把它当成一张“临时的虚拟的表”来使用。
题目:查询员工的id,salary,按照department_name 排序
在ORDER BY 中使用子查询:
SELECT employee_id,salary FROM employees e ORDER BY ( SELECT department_name FROM departments d WHERE e.`department_id` = d.`department_id` );登录后复制
EXISTS与NOT EXISTS关键字
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
如果在子查询中不存在满足条件的行:
条件返回 FALSE
继续在子查询中查找
如果在子查询中存在满足条件的行:
不在子查询中继续查找
条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
SELECT employee_id, last_name, job_id, department_id FROM employees e1 WHERE EXISTS ( SELECT * FROM employees e2 WHERE e2.manager_id = e1.employee_id);登录后复制
子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表
进行条件判断,因此在大部分 DBMS 中都对自连接处理进行了优化。
【转自:建湖网页制作公司 http://www.1234xp.com/jianhu.html 欢迎留下您的宝贵建议】