
Mysql表连接的执行流程是什么
1. 前言
对于连接操作,驱动表和被驱动表的关联条件我们放在on后面,如果额外增加对驱动表和被驱动表的过滤条件,放到on或者where后面都不会报错,但是得到的结果集却是不一样的???
1.1 mysql连接的原理
众所周知,mysql是基于嵌套循环连接(Nested-Loop Join,暂不考虑优化算法)算法来进行表之间的连接操作的,大致过程如下:
选取驱动表,使用与驱动表相关的过滤条件执行对驱动表的单表查询;
对于查询到的驱动表中的每一条纪录,分别到被驱动表中查找匹配的纪录。
伪代码如下:
for each row in t1 { // 遍历满足对t1单表查询结果集中的每一条纪录
for each row in t2 { // 对于某条t1纪录,遍历满足对t2单表查询结果集中的每一条纪录
if row satisfies join conditions, send to client
}
}登录后复制1.2 show warnings命令
我们写的sql语句,在经过优化器优化后才会交给执行器执行,而show warnings命令则可以帮助我们获得优化器优化后的sql。
2. 准备工作
表结构如下:
CREATE TABLE `student` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `stu_code` varchar(20) NOT NULL DEFAULT '', `stu_name` varchar(30) NOT NULL DEFAULT '', `stu_sex` varchar(10) NOT NULL DEFAULT '', `stu_age` int(10) NOT NULL DEFAULT '0', `stu_dept` varchar(30) NOT NULL DEFAULT '', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `uq_stu_code` (`stu_code`) ) ENGINE=InnoDB AUTO_INCREMENT=43 DEFAULT CHARSET=utf8mb4 CREATE TABLE `course` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `cou_code` varchar(20) NOT NULL DEFAULT '', `cou_name` varchar(50) NOT NULL DEFAULT '', `cou_score` int(10) NOT NULL DEFAULT '0', `stu_code` varchar(20) NOT NULL DEFAULT '', PRIMARY KEY (`id`) USING BTREE, KEY `idx_stu_code_cou_code` (`stu_code`,`cou_code`) ) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8mb4登录后复制
表数据如下:
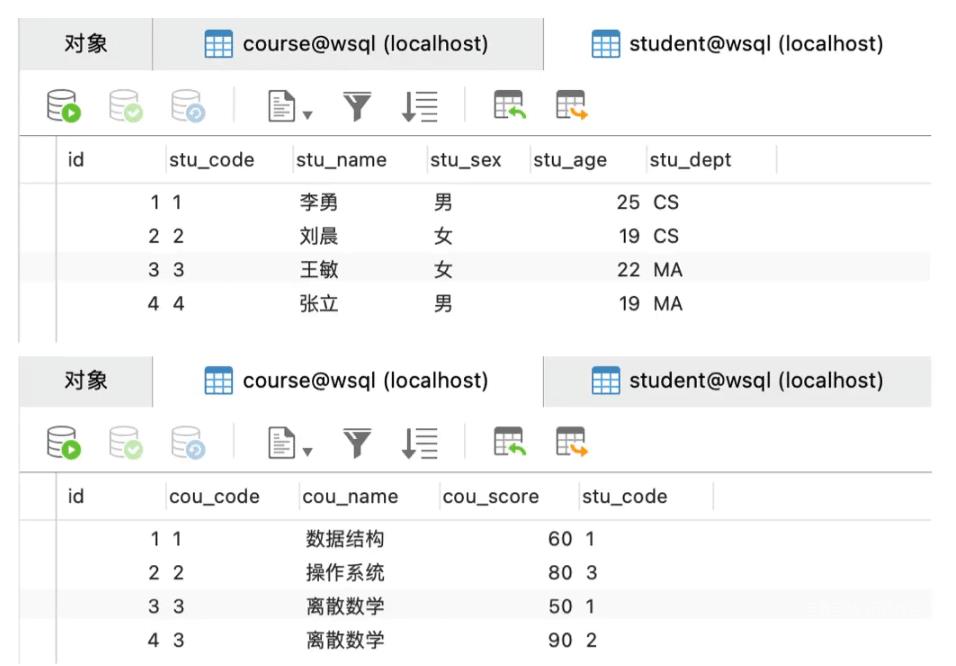
3. inner join内连接on、where的区别
sql如下:
select * from student inner join course on student.stu_code = course.stu_code and student.stu_code >= 3 and course.cou_score >= 80;登录后复制
执行explain+sql命令:

执行show warnings命令:

分析:从show warnings分析来看,对于inner join连接,经过优化器优化后,on连接条件会转化为where!也就是说内连接中的where和on是等价的。
4. left join左连接on、where的区别
4.1 where驱动表过滤条件
sql如下:
select * from student left join course on student.stu_code = course.stu_code where student.stu_code >= 3;登录后复制
执行explain+sql命令:

执行show warnings命令:

结果集:

分析:从explain分析看出,student作为驱动表,把student.stu_code >= 3作为过滤条件进行全表扫描,然后把查询到的每条纪录的student.stu_code(也就是on条件里面的)分别作为过滤条件让被驱动表course做单表查询。
4.2 on驱动表过滤条件
sql如下:
select * from student left join course on student.stu_code = course.stu_code and student.stu_code >= 3;登录后复制
执行explain+sql命令:

执行show warnings命令:

结果集:

从结果集来看,student.stu_code >= 3并未生效,为什么?
分析:从explain分析看出,student作为驱动表,做全表扫描,然后把查询到的每条记录的student.stu_code和student.stu_code >= 3(也就是on条件里面的)分别做为过滤条件让被驱动表做单表查询;此时student.stu_code >= 3对驱动表是不过滤的,仅在连接被驱动表时生效,查询不到符合纪录而返回NULL!
4.3 on被驱动表过滤条件
sql如下:
select * from student left join course on student.stu_code = course.stu_code and course.cou_score >= 80;登录后复制
执行explain+sql命令:

执行show warnings命令:

结果集:

分析:从explain分析看出,student作为驱动表,做全表扫描,然后把查询到的每条记录的student.stu_code和course.cou_score >= 80(也就是on条件里面的)分别做为过滤条件让被驱动表做单表查询;
4.4 where被驱动表过滤条件
sql如下:

执行explain+sql命令:

执行show warnings命令:

结果集:

从show warnings分析来看?left join连接变成了inner join连接?
分析:从show warnings分析看出,如果被驱动表有过滤条件在where,那么left join会被失效,被优化成inner join连接。所以被驱动表的过滤条件应该放在on而不是where。